
On rethinking coursework expectations in the era of AI: Raising the floor and the ceiling
What we can learn from high school English teachers and frontier AI model benchmarking


After a wild two months of basically touring the country to give AI workshops and trainings for conferences, academic departments, non-profit leaders, and research teams, the same question has come up in every single room: So what are we going to do about teaching and learning in the era of AI?
This is a super complex issue that has no easy or blanket answers, but what I’ll aim to do in this shorter (setting a self-intention here) post is suggest a few lines of challenging thinking to get people stirring around the possibilities. I think there are two really nice analogues/parables I want to surface that should get us moving in a productive direction: the first comes from my days as a public high school English teacher battling students about SparkNotes summaries, and the second comes from how we’ve come to measure progress and “benchmark” the capabilities of frontier AI models against one another. And note that I’m going to focus on the college/university teaching context rather than the K-12 context, at least in part because I think there are a LOT more complications when you throw younger minds and cognitive/emotional development into the mix.
So first, let’s lay out a basic mental model. The research on this frontier is quite messy and still coming to grips with what AI is actually capable of as of right now (as is the case with anything related to researching AI’s impacts and consequences, frankly), but my distillation of the current consensus is roughly:
Learning new things is, and should be, hard (i.e., “productive struggle” or “zone of proximal development”). Obviously, arbitrary difficulty is not desirable/useful at all -- but short-circuiting the sort of necessary engagement and effort inherent in really grappling with learning a new thing (whether with AI, human tutors, explicit cheating, overly involved parents, etc.) likely leads to less durable and sustained learning over time (see, e.g., Rismanchian et. al, 2026).
The growing capabilities of AI assistants makes this short-circuiting of difficulty while learning both easier than it has ever been, and more immediate. When a student can avoid the difficulty of grappling with a hard reading or a complex concept by asking the ever-present ChatGPT to summarize it for them, very little learning is happening, even if they might go on to perform fine according to current assessments/assignments (but very likely not!). Inappropriate use, and/or extended use, in this direction seems to cause reductions in general understanding, task performance, and skill acquisition (i.e., “cognitive surrender” and “cognitive offloading”).
These two dynamics together are a very bad time for anyone trying to teach right now, because it means that students may be sailing through assignments better than they ever have, on average, at the same time as they learn less than before.
So what do we do about it?
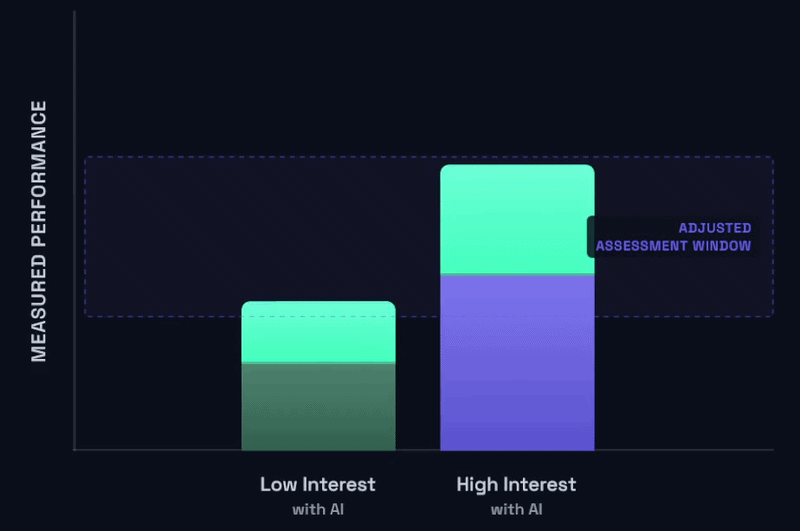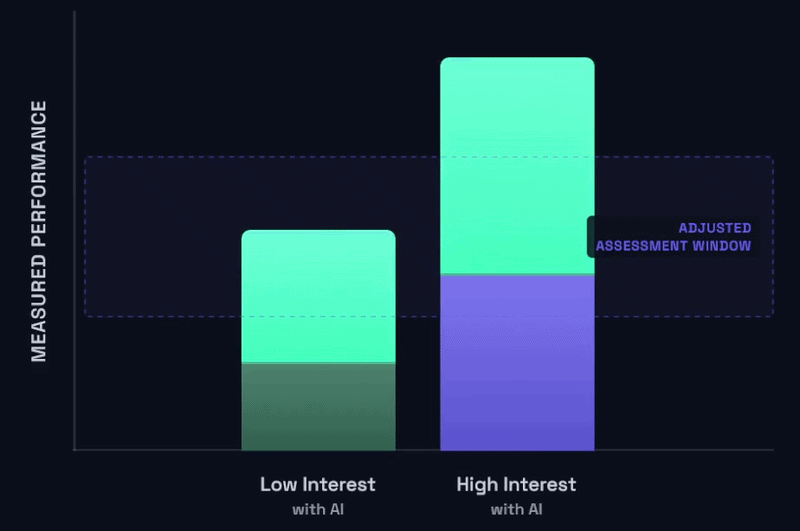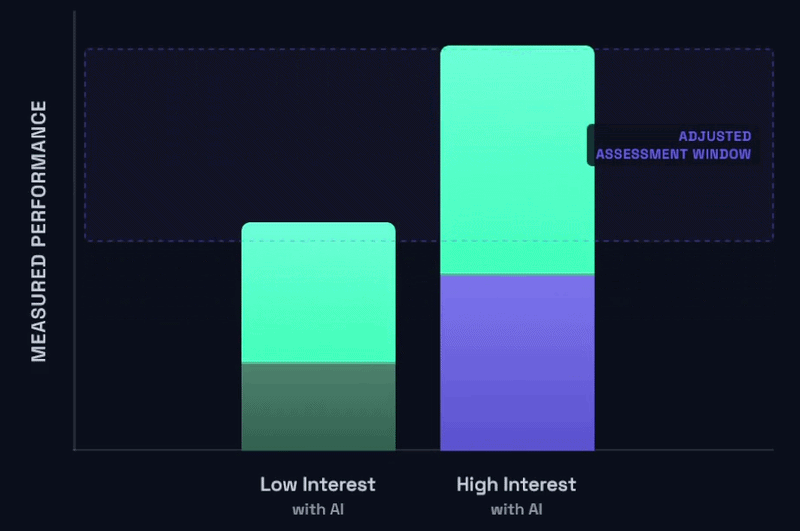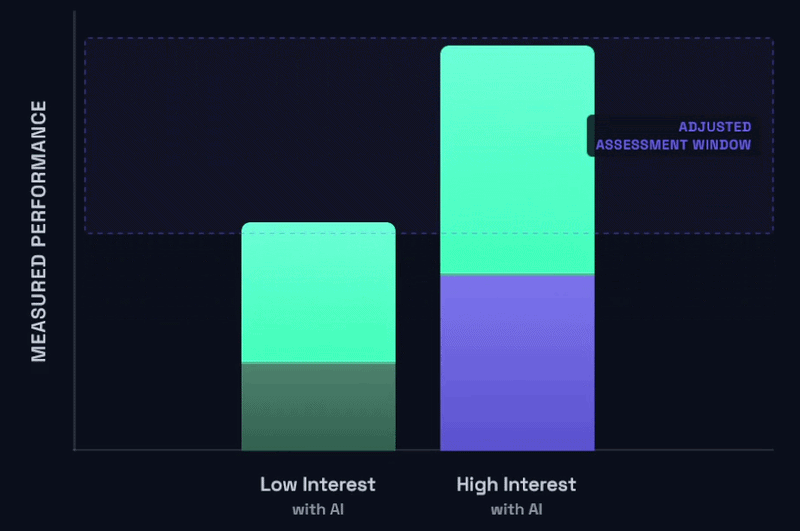
There are a few ways to think about this dynamic when it comes to assessing students’ learning. Going with a simple visual model, imagine we have exactly two student types: a higher-achieving/engaged/motivated/effortful/focused student, and a lower-achieving/disengaged/unmotivated/lazy/distracted student. Use whatever words you want, you get the idea; I’ll call them “High interest” and “Low interest” for short. In an ideal state, we measure how students are doing with an assessment and the results look something like this:
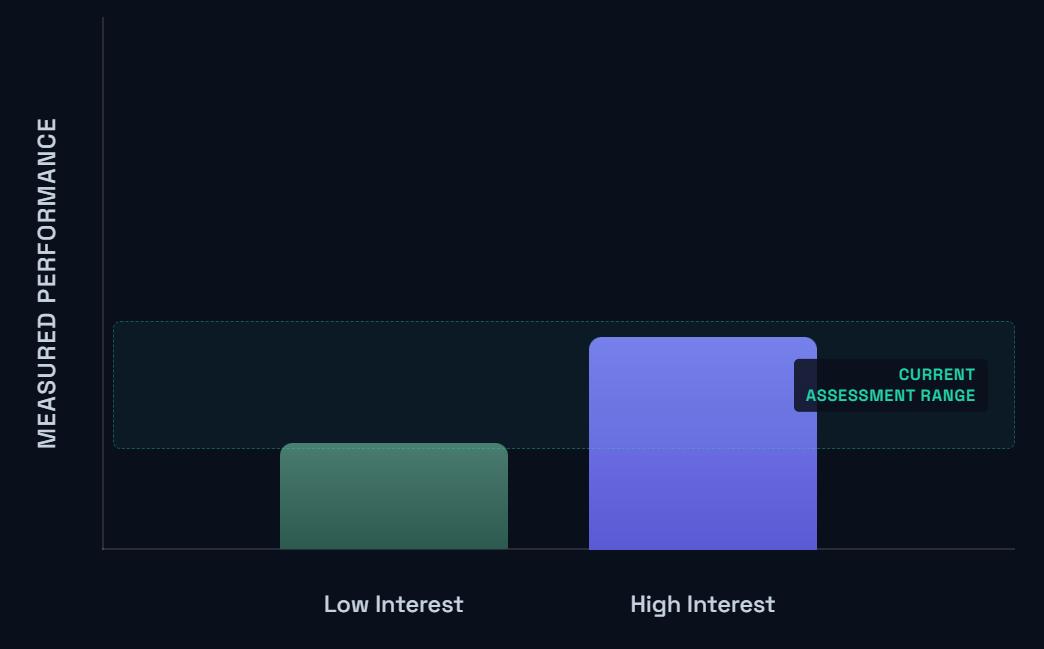
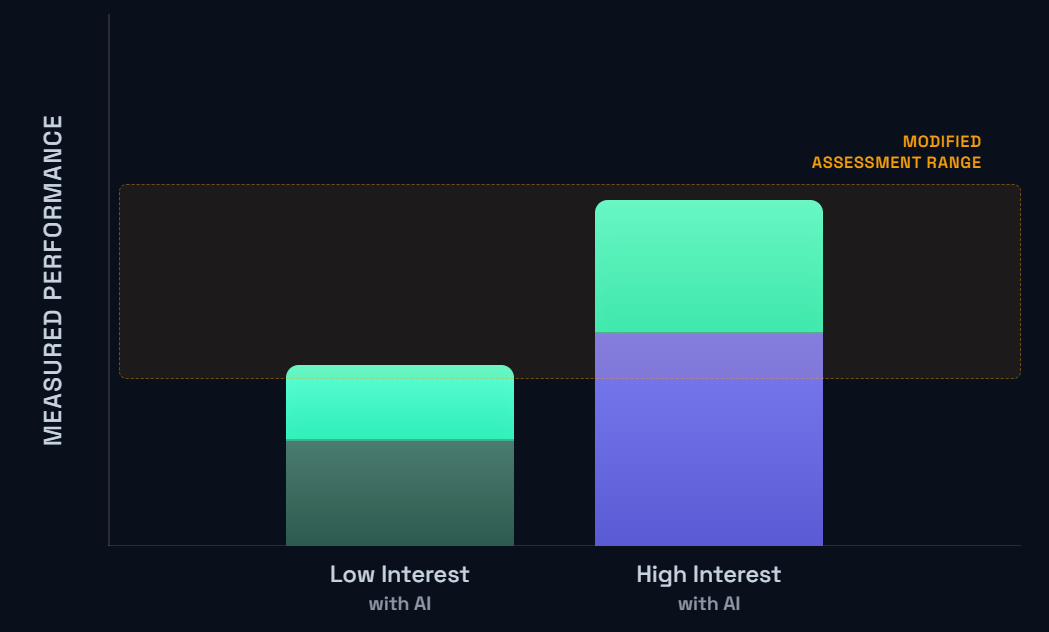
Now, in a pre-AI world, this is all fine and dandy. But the unfortunate reality is that things are starting to look a lot more like this:
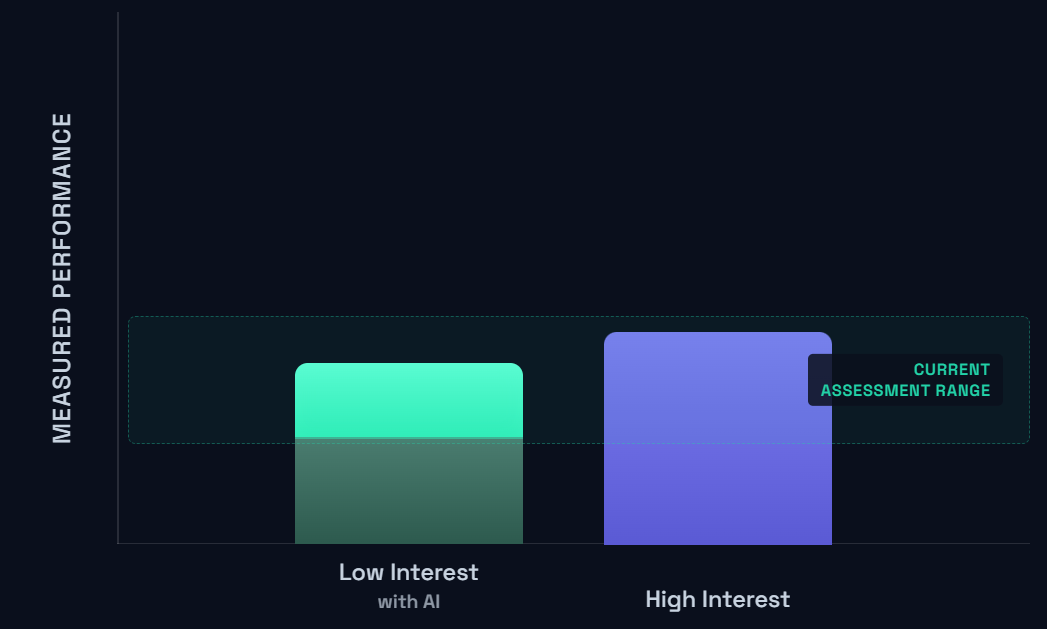
In other words, Low Interest students can start to look very, very similar on assessments and assignments as High Interest students when they leverage AI.
Given these circumstances, instructors seem to be struggling with two very bad options in front of them to ameliorate this. The first option is to try and heavily police student AI use to make this plot look more like the pre-AI plot by making it difficult or impossible to use AI for assignments where possible. We’re talking proctored exams, written exams, oral exams, and so on. The second option is to perhaps surrender to the use of AI by some students, but do more to try and distinguish the students from one another by becoming more particular and specific about what “success” actually looks like. Roughly speaking, that looks something like this:
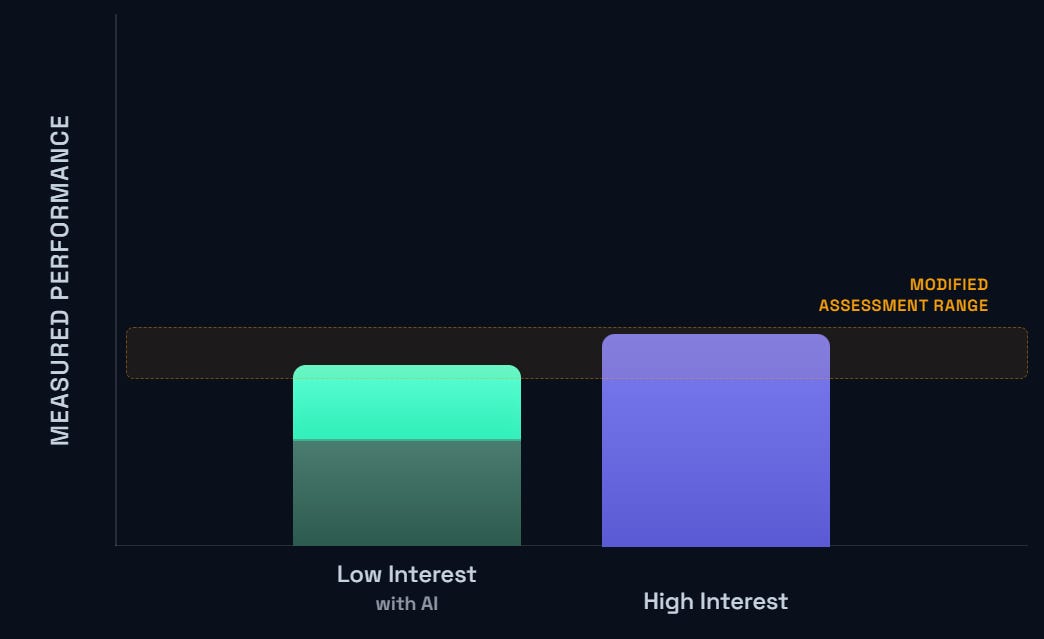
Based on what I’ve heard from colleagues via workshops and social media, neither of these tacks seem to be particularly successful or enjoyable by anyone involved.
So let’s talk about a third option, which importantly may not be available and/or tolerable to everyone given constraints on institutional policies, field- and topic-specific alignment, and your own disposition towards the proliferation of AI in society. But let’s talk about it.
First: Raise the floor
The modified assessment range pictured immediately above is maybe directionally correct, but how we adjust the assessment range and why matters a lot.
When I was an English teacher, I taught 9th and 11th graders up in Maine at a public high school. One thing that was always a struggle at the time was students’ use of SparkNotes. For those who don’t remember or aren’t aware, SparkNotes is basically a study guide platform that served up chapter-by-chapter summaries, essay topic ideas, reading guides, etc., for basically all the major books English classes would cover. The problem was that a student could choose not to do any of the actual reading assigned for class, quickly read the SparkNotes summaries for the assigned reading instead, and show up to class discussion/assignments conversant enough in the material to pass by undetected.
This meant low interest students were able to completely short-circuit the important parts of both having actually read and engaged with the material, as well as synthesized their own thoughts and ideas from it. The summaries they read were often hyper-generalist and ended up directing students into a sort of mediocre-but-not-wrong mindset about the main themes and ideas of a given piece of literature. Sounding familiar?
My imperfect, but I think useful, strategy at the time was simple: Some students will take the path of least resistance. Embracing this aspect of human nature and understandable student circumstances, how can we make a path of least resistance that is still useful for their learning and engagement? It’s not super important to dig into the finer design/details, but I started crafting something I called “Reader’s Guides.” The basic goal of this assignment structure was to:
Literally hand students the exact passages that I felt were most important to understand for upcoming class discussion and more involved textual interpretation down the road (e.g., summative essays, debates, projects, etc.)
Ask directed but open-ended questions that low interest students could answer using the selected passages alone, and that high interest students could enhance substantially with evidence from passages beyond them

It was a version of, “If you can’t beat them, join them and do it better.” I wanted to hand students a better shortcut, basically telling them: Listen, if you don’t have time, just open the actual text and read these segments -- it’s easier than trying to dig around on SparkNotes, and it’ll get you farther anyway. Not everyone loved this strategy, and there are definitely critiques to level here, but it worked very well for my intentions.
The wins ended up being on both frontiers: first, the low interest students would actually look at the text itself and engage. Some at a cursory level, of course -- but many went on to engage beyond that because the door was wide open, and there was no inertia to overcome to genuinely re-engage with the actual material as there was with SparkNotes. Second, the high interest students found it to be a useful outline and starting point for their notes and thinking (especially high interest students who struggled with harder texts and could use it as scaffolding).
The point of this example is to encourage current instructors to ask the same question of our assignments today, in the era of AI. How can we structure our assignments in a way that the path of least resistance via AI still offers some genuine value for students? How can we manipulate the assignment context and parameters in such a way that we can control what that looks like and encourage at least a cursory level of engagement and learning even in the worst case scenario?
A toy example: Students are going to submit a written assignment for your class. Applying the thought process above, we’d say: Okay, the path of least resistance is that students dump a bunch of course materials into ChatGPT or NotebookLM and get a finished document out, and hand that in. But what if we didn’t allow that to be the end of the story? What if we assume some students will do this, and what would it look like to secure at least a small victory for their learning while outright enhancing the learning of those that don’t? One suggestion: require students to use their AI assistant of choice to review their draft before submission, and then have students submit:
Their original draft
A few paragraphs’ synthesis of what their AI assistant got right and what their AI assistant got wrong in the review
Their updated draft
Low interest students who weren’t intending to take the assignment seriously now have to grapple with the fact that any initial slop from an AI is not necessarily worth taking naively and need to engage at least with one or two more steps of cursory engagement. High interest students who weren’t intending to use AI at all now critically engage with outside evaluation of their own work and get reps in with the very necessary and increasingly important skill of taste-making and discernment with respect to AI output. To the extent the AI gives awful advice or amazing advice, the high interest student benefits. You really only need to look at #2 and #3, which adds relatively little in the way of grading volume/burden at the end of the day.
This mindset will have varying applicability across different assignments, fields, topics, and courses, but I think it’s increasingly important for us as educators, and valuable for students themselves, to be thinking creatively about how we can encourage a more sustained engagement with course material AND critical engagement with AI tools even among students taking the path of least resistance.
Second: Raise the ceiling
Raising the floor in that way is just half of the equation, so let’s return to one of the earlier visual diagrams for a moment:
If you’re in a situation that looks like this, one could state it bluntly as: a low interest student with minimal effort and intending to invest the least amount of time possible can now naively corral a basic AI assistant to trivialize the vast majority of your assignment. Now that sucks, and I hate that for all of us. It is not good, and it is a disservice to the effort and intention you’ve put into your coursework and your students’ learning.
But I want us to shift our attention away from the low interest student for a moment (the “raising the floor” section was really meant for them), and let’s focus on the high interest student for a moment. Why would it not be the case that a high interest student, with genuine effort and intending to invest meaningful time with thoughtful and creative use of complex AI support should blow the sky off your existing expectations of the assignment? And I would venture to argue that these high interest students stand to gain even more from judicious and creative use of AI as described than the low interest students. That would start to look something like this:
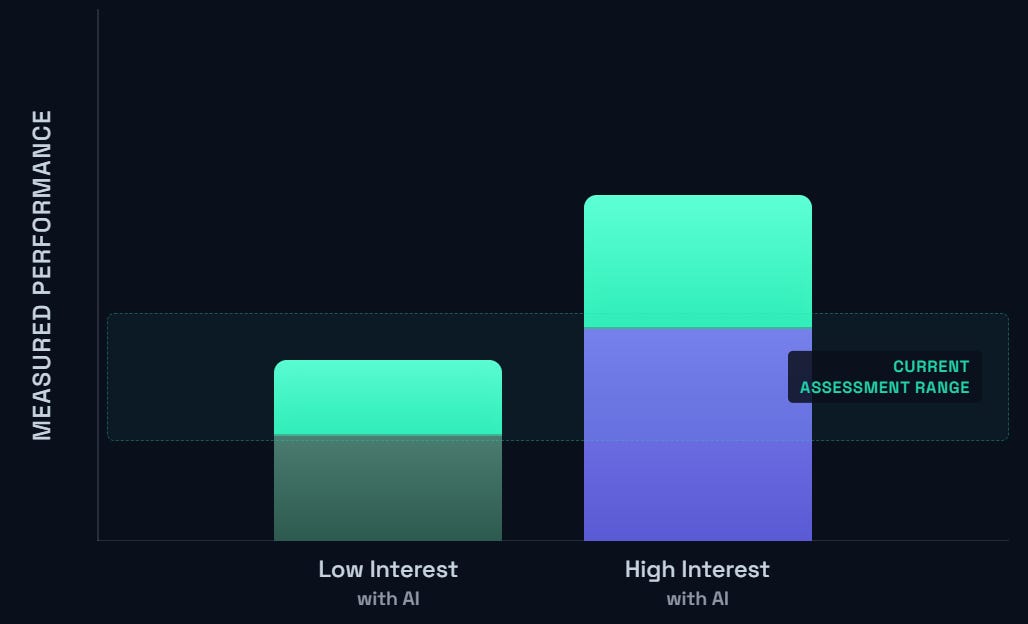
Before we talk much more about that concept, let’s talk about the second parable of AI benchmarking.
Put briefly: as AI models get better and better, it has become increasingly critical that we understand how they’re getting better, and by how much. If you’ve been following the contents of any major AI model release from the frontier labs recently, you’ll recognize images like this:

We call this process benchmarking. Teams across the data science and machine learning frontier have been doing this for ages, but the basic strategy is for labs and researchers to come up with complex batteries of tests that any AI model can be pitted up against, and new models’ performance on said tests can help us understand the relative power/capability of that model against other models in a fair comparison. Each row in the image above (a summary of benchmarking for Anthropic’s Fable 5 model) represents a different kind of benchmark test used across the industry: SWE-Bench Pro, FrontierCode (Diamond), OSWorld-Verified, etc. etc. Each column represents a different AI model’s score on said benchmark, allowing us to (selectively!!) compare results and describe (imperfectly!!) where the state-of-the-art is. It’s not important that you understand what each one is or does exactly, but just know they each represent a different angle of evaluation and attack to see how different models do under different testing batteries.
Contrast the benchmark results above for Fable 5, released in June 2026, with the press release and benchmarking results for Claude Opus/Sonnet 4, released just one year earlier in May 2025:
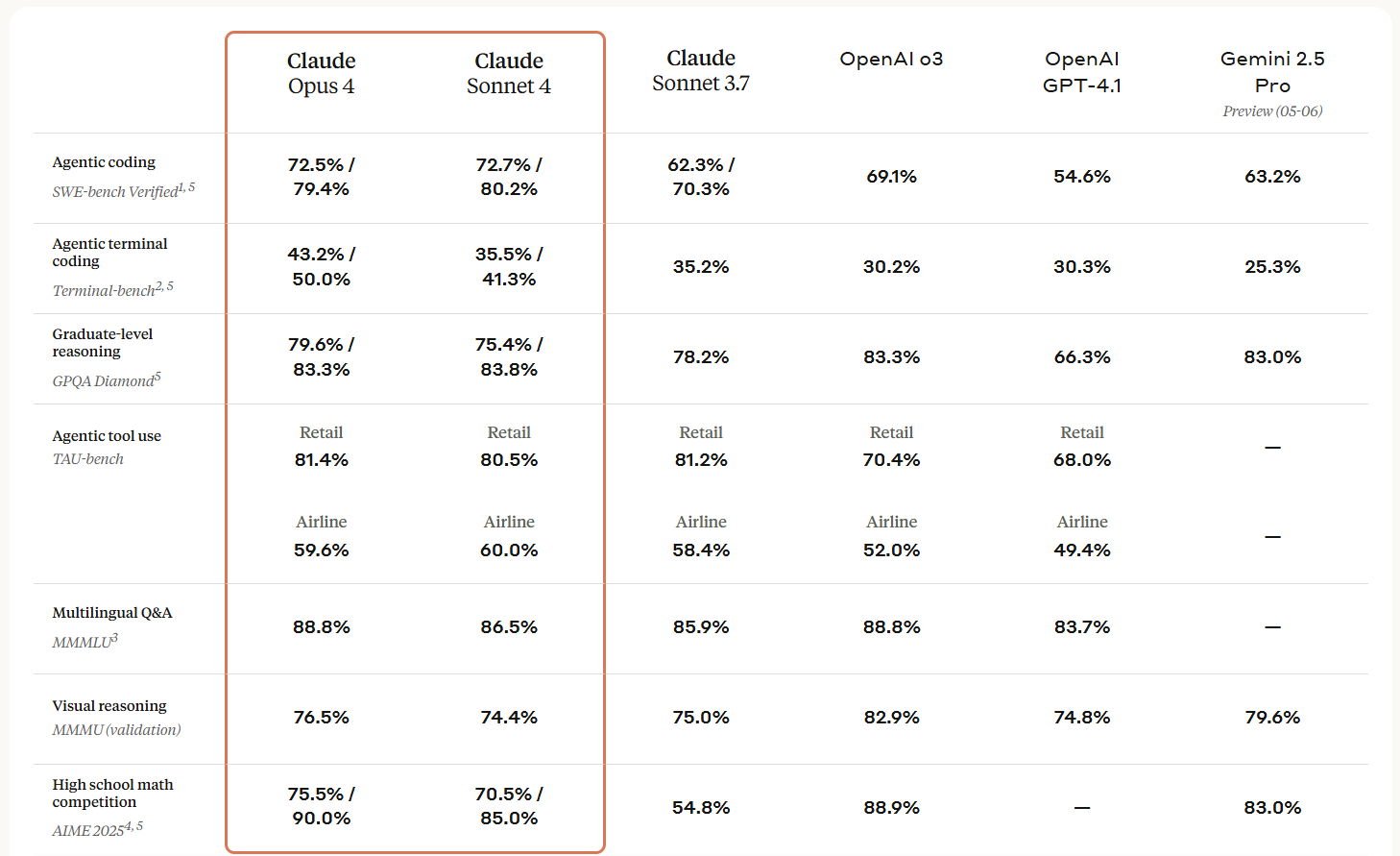
The benchmark tests used here are SWE-bench Verified, Terminal-bench, GPQA Diamond, and so on. If you’re looking closely, you will not see a single one of the same tests across these two images, only one year apart. Why is that?
One reason is that when a mainstream benchmark is released and frontier labs start using it, they start optimizing for them during model development. Internally as Anthropic or Google or OpenAI develop new models, they’re constantly checking to see, “Well how well does this new draft version of our model do against X benchmark?” You might hear this colloquially referred to as “benchmaxxing” now, or Goodhart’s law with a new coat of paint: “When a measure becomes a target, it ceases to be a good measure.”
The point is that, eventually, every major model release begins to blow the benchmark scores out of the water. If every model gets about the same high score on a benchmark, that benchmark is said to be “saturated,” and it stops being a useful differentiator of how good one model is versus another. Labs and researchers are constantly developing new and harder benchmarks for this very reason: As models get better and better, we need more difficult and complex testing batteries to distinguish them from older models and from one another.
What I want to suggest is that your assignments are very likely saturated in this same way. The way you’re structuring your assessments has stopped being a useful way to delineate student ability, effort, engagement, and learning in this paradigm, and we need to think about how we can develop that next wave of “benchmarks” that raise the ceiling, raise the bar on our expectations for what is possible in a given assignment. That looks something more like this:
We reposition the floor to what’s possible with AI at a naive, low-effort, low interest level, and we reposition the ceiling to what’s possible with AI at a complex, high-effort, high interest level.
A toy example: I co-taught a course in basic data management practices for social science grad students back during my doctoral program. We covered things like reproducible workflows, basic exploratory data analysis and data visualization with Stata, etc. Our end-of-the-semester assignment was basically: Take some public raw datasets, clean them and join them, generate a bunch of nice data visualizations, run some basic descriptive analyses and interpretations, and write up a nice memo synthesizing insights about some of the key findings related to a simple research question.
I don’t want to freak anyone out (and hopefully this isn’t a surprise to people anymore), but this whole-semester assignment is now doable in about 30 minutes of human effort with the right AI orchestration systems. You could probably still get it done in closer to an afternoon of focused work going simpler (i.e., vibe-coding in Claude Code or Cowork).
So what would it look like to adapt our standards and expectations for assignments accordingly? What kinds of intensive, involved, and interactive inquiry could we demand of students now that the marginal cost of another data visualization and data robustness check is nearly zero? What degree of intimacy of understanding can we expect from students about their datasets when developing flexible dashboards and rapidly iterating/improving/revising data processing pipelines is an afternoon’s work? How can we encourage students to cultivate and demonstrate critical intuition about the potential pitfalls, failure states, limitations, and errors of their data work that are actually no less robust and measured than our own -- and, ideally, ultimately superior?
If these questions I’m raising for my former data management students sound a whole lot like the sorts of questions I’ve been raising for my peer researchers regarding use of AI in their own work lately, you’re right.
But anyway, let’s get concrete for this example. First, let’s raise the floor: What if we ask students not just to produce this fully reproducible analytic pipeline and artifacts, but also document (in a nice and orderly fashion) the exact battery of intuition checks, interrogative questioning, robustness verifications, supplemental analyses, and exploratory questions across stages that they pressed their AI assistants for to ensure they knew what was happening and that it was as intended? We can demand not just that students produce the artifact, but that they’ve done their due diligence to understand whether and to what extent they can really stand by the quality of said artifact -- even if they ultimately sailed through with greater levels of AI assistance than we’d like. The bonus: You have a clear sense of what failure modes they’ve missed that you can more readily check with support of AI yourself, and that should be part of the feedback and critique you provide back to them to help them improve.
Next, let’s raise the ceiling. If data communication and storytelling is a core value in said class (I strongly argue it should be!!), let’s ask students not just to produce a data visualization for each key insight, but a battery of options for data visualizations for each key insight. Ask them explicitly to iterate on a variety of plot styles, framing, levels of interactivity, levels of animation, etc., and iterate towards their final version (documenting the trail of candidates); ask for a minimum of 10 meaningfully distinct prototypes per key plot. Some are going to be garbage, and some are going to be phenomenal beyond your or their initial imagination; students will have to (get to) demonstrate taste and discretion and creativity, and what they produce in the end is almost necessarily going to be better than what they could’ve before through this wider iteration cycle.
Your imagination with, and understanding of, AI is the binding constraint
You might immediately say, “Brian that sounds like a completely unreasonable amount of work to ask of a student” -- yes absolutely… in a pre-AI world. In a world where students have access to Claude or ChatGPT, this is three to four well-crafted prompts, an hour of sifting through candidate results, and then another 30 minutes of polishing the final version (important caveat: you should probably know what exactly are students’ allocations for AI use on their accounts before you require highly intensive AI work!). Let me put it another way: if your reaction to an initial suggestion for raising the ceiling is not a reflexive “Oh my god that sounds insane”, you’re probably not actually raising the ceiling. You genuinely need to think bigger.
This is a type of imagination and creativity that I think we all need to start broaching now, and it’s especially urgent to start thinking along these lines because:
What the new ceilings should look like will vary significantly between fields, topics, disciplines, tasks, etc., and no one can really know what that looks like outside of the current experts (i.e., you!). As I mentioned explicitly above: Not every assignment is as amenable to this as the examples I’ve picked out, but I suspect anyone who’s struggling with the issues of student AI use in a given assignment as described above has, by corollary, meaningful opportunity to explore and apply the raised floor/ceiling concepts raised here.
Your ability to think creatively about what the raised ceiling can/should look like is going to be directly constrained by your understanding of what is currently possible with thoughtful and careful use of AI in your field. If you don’t have a sense for what opportunities exist about your work with respect to AI, I’m not sure how you can productively or accurately think this through on behalf of your students.
For that reason, your students’ ability to tackle the raised ceiling is also going to be a pure function of your ability to demonstrate and model these new skillsets and disciplinary opportunities for them in your actual classrooms and labs. The apprenticeship model remains extremely valuable here: people often can’t do what they haven’t seen: so you have to show them and practice with them. E.g., no graduate student ever learned to give a genuinely good conference talk by just reading online guides; they need to see their PI and peers do it well and poorly, and they need to do it themselves poorly and then well with feedback. So how can you make similar opportunities for them to see responsible and rigorous use of AI along the lines of what I suggested above within your classroom, from you, so that you can ask them to do the same in your expectations of their assignments and coursework?
The ceiling will need to keep moving as AI models themselves improve. I don’t think it’d be radical to suggest that as AI gets better and better, any assignment you could make today will be saturated a year from now. That’ll probably look like this, over and over again:
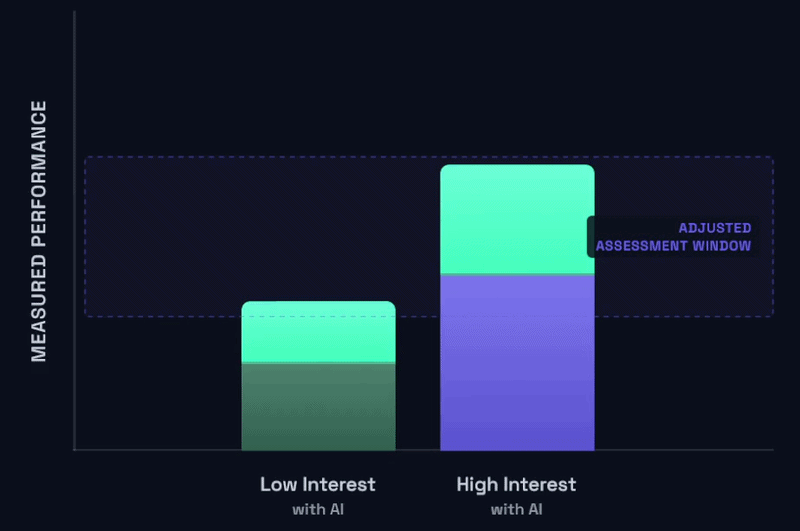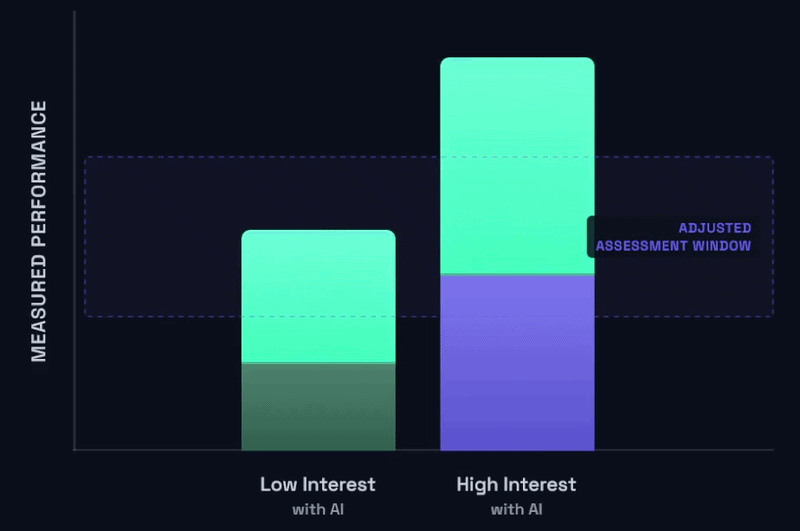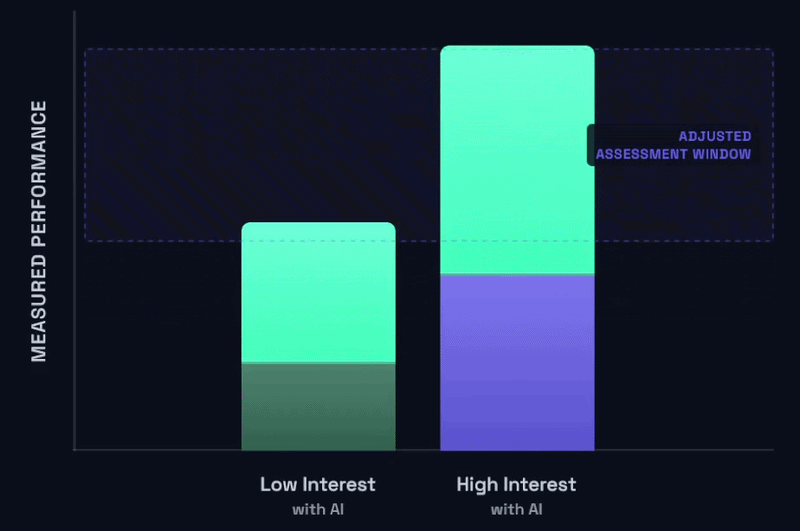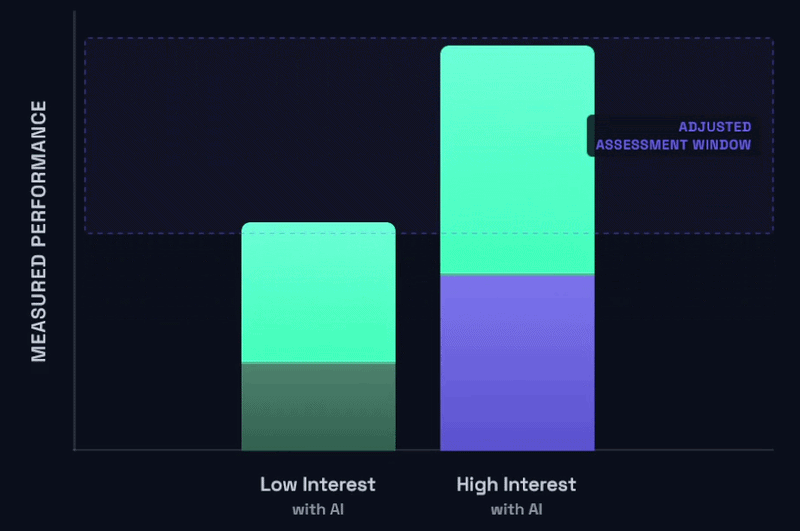
And… well, with models like Fable coming out and no slowdown to that rate of improvement in sight, it’s going to be a very interesting question as to what it means for all of us when the human component of the bars shown above start to become the minority of the overall bar. But let’s not broach that conversation for now.
If you’re feeling a bit overwhelmed by those four bullets together, you’re definitely not alone. This is a crazy, crazy time, and I’m honestly not entirely sure where this leaves the modal college instructor: someone who probably is not compensated enough for their teaching efforts, who has a huge variety of other responsibilities (some of which they care about a lot more), and who is not given particular agency/autonomy over how to revamp materials especially in light of broader policies/restrictions on AI use more generally at their institution.
So to the extent that you, the person actually reading this right now, are not immediately struggling with said constraints, I implore you to take very seriously the opportunity to engage with this reimagining of the floor and the ceiling in this new environment on behalf of others in your field. To the extent you can create room and space and time for these discussions among junior faculty or colleagues, I think it serves everyone to do so. And to the extent you can engage with your students themselves in discussing this, I think they and you will be all the more clear-eyed for it.
I also want to be clear: despite how it may sound, my position is not that everyone should be using AI in their research and in their work (though there are many who seem to be arguing that vociferously; I frankly disagree with them). My position is that everyone needs to have a critical and nuanced understanding of AI to be able to make that decision in the first place for yourself and for your students in a genuinely informed way -- and that necessitates getting your hands dirty with AI and earnestly testing things out for yourself [see more on my thoughts for how to do that more concretely in this post; and please do see my note re: conflict of interest in the appendix below!]. Given the rate of AI capability progress at this time, it’s also not tenable to think you just need to do your due diligence once and make a final decision; this is a constantly moving target you need to engage with. The number of people who I know haven’t yet updated their perceptions of AI since mid-2025 is striking and alarming given how radically different the landscape has become. I really honestly don’t like it any more than you do (don’t ask me about my work-life balance and mental health lately since going full-time on AI work!), but I think the reality is that this is the nature of the beast and the era of AI we now live in, whether we like it or not.
Again, my goal with this post is not to suggest that these are silver-bullet solutions for everyone to overcome to these radically complex problems, but I do hope these examples and ways of framing can spur useful discussion and intuition for directions to start moving in. They won’t apply to everyone, and they certainly aren’t the end of the conversation, so I’d love to hear: Does any of this land with you in your courses, your field, your assignments? Why, why not, and how so? Have you already been playing with these concepts in some way, and if so, what has that looked like? I’d genuinely love to talk through your current problems of practice/assignments and see what we can come up with together in comments.
That’s all for now; sorry this post was yet again way longer than it should have been (“shorter post today” womp womp). In any case, now that I’m doing less work travel over the summer, my goal is to try and release more digestible posts on a weekly-ish cadence. Til next time!
Appendix/Notes:
I want to acknowledge what might appear like a complete conflict of interest: here I am, telling you its urgent and important for the good of society to explore uses of AI in your/your students’ work… because I run a business teaching people how to explore uses of AI in their work. That’s a very reasonable interpretation, but I’m going to actually flip the causality on its head: I run a business teaching people how to explore uses of AI in their work because I think it’s urgent and important for the good of society to explore uses of AI in your/your students’ work.
I’ve said directly to clients and colleagues that I am very explicitly trying to work myself out of a job here by sharing and open-sourcing basically all the materials I’m producing along the way (much more to come via Substack and YouTube now that I’ve done all that workshop work over the past month!), and I am very much excited for a day where teaching others how to do this stuff stops being a part of my day-to-day: not because I hate the teaching (I love teaching!), but because it means so so so many amazing things for the state of scientific progress in our society if that’s the case. And it means we’ve moved well past this (frankly) dangerous and confusing and disruptive time with a lot of inherent collateral damage.
To put a fine point on it: the vast majority of material for this post was initially created as part of a paid workshop I crafted for a client. I’ve got 2-3 more posts distilled from that same workshop on the way, all of which will be free and readily accessible to everyone via this free blog. The business model is very explicitly people paying me to come up with the materials, and then me sharing them for free after.
You obviously don’t have to believe me, but I hope my pro bono and open source portfolio can ultimately speak for itself!