
Why no one can agree about AI progress right now
A three-part mental model for making sense of this weird moment on the AI frontier


At time of writing, it feels like there are exactly two camps battling openly in the AI discourse right now:
People who believe that AI/LLMs are fundamentally flawed and can never truly be a threat to many/most types of human work and labor
People who believe we are only a handful of months away from full labor market collapse due to how rapidly AI/LLMs can now replace entire industries
You’re probably seeing it play out in your own professional circles and friends, and you might yourself strongly identify one way or the other. Why is there such a stark divide on what AI can and cannot do when we’re all roughly looking at and using the same things? Even within the very same fields that are allegedly being the most disrupted (e.g., software development), there are people at either pole claiming vehemently that the other side are ill-intentioned, bad-faith actors. Is it that one side is simply full of ignorant luddites too blinded by their own desperate self-preservation? Or is it that the other side is simply full of AI grifters too blinded by their own self-interest and dire need to keep the investor gravy-train rolling?
As I think more and more about what makes DAAF work, as well as why I think it has only recently become possible for a tool like DAAF to even exist (imo, circa the release of Opus 4.5 in November, 2025), I think I have an explanation that reveals why both sides are surprisingly more justified than we might initially expect: Too many people are thinking about AI progress as one singular measure focused on purported frontier model quality, when it is really three intertwined and interdependent measures.
Now, the model-specific focus is an understandable way to think about things: This is the visible frontier that every AI company touts, and that the average end-user tends to see and remember most readily. Opus 4 is now Opus 4.5 is now Opus 4.6! GPT4 to GPT5 to GPT5.2 and then GPT5.3! Gemini is now Gemini Pro and Gemini Flash and is better and more capable than ever! Wow! But this simplistic impression from the marketing is what’s leading us to the current state of the deeply disillusioned camp versus the overly-hyped camp.
While the raw model capability is absolutely a core component of how we should be thinking about AI progress, this is missing two additional dimensions that kind of change everything, at least in part because they’re currently pretty obscure to the regular person who’s only occasionally dropping into ChatGPT or NotebookLM as a casual user.
A better mental model: The Mind, the Body, the Instructions
A complete picture for understanding the frontier of AI progress, and what AI can actually do, requires then three total core pieces:
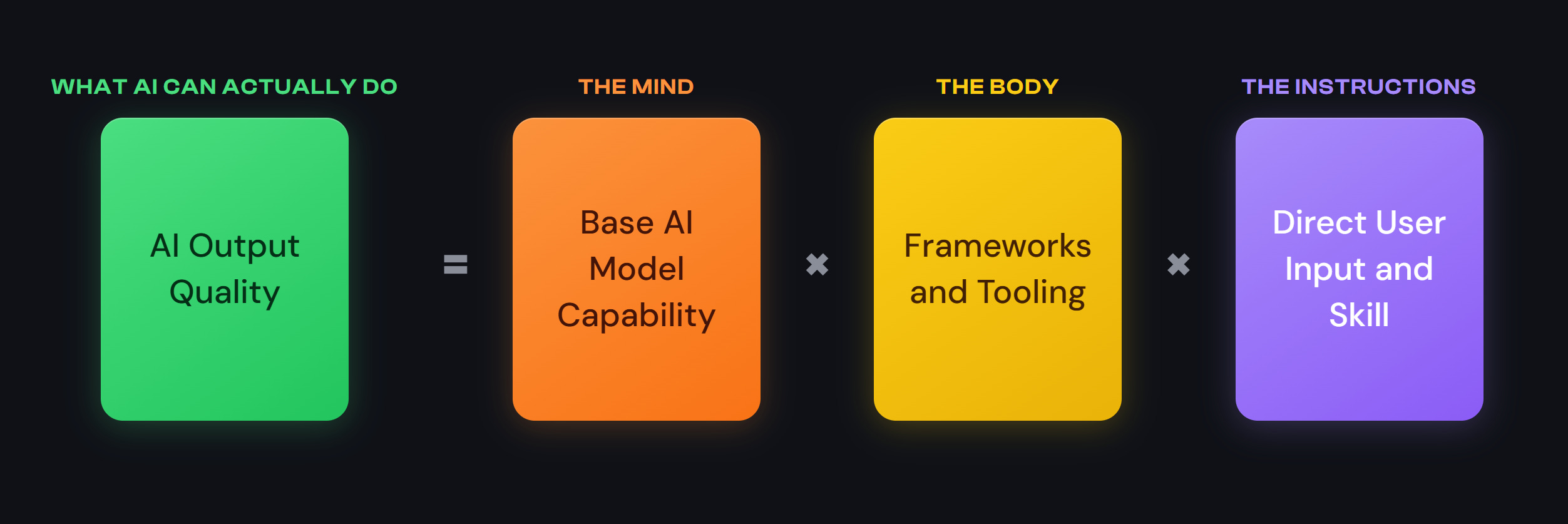
“The Mind”: Progress in base AI model capability. I.e., the big model advancements we see in the news and usually result in a model having more training data, thinking in more complex ways, and generally able to take in more contextual info before acting.
“The Body”: Progress in accompanying AI orchestration frameworks and tooling. I.e., infrastructural advancements allowing models to run code scripts at will, or search through provided files/the internet dynamically, or delegate a task to another fresh AI/LLM, or load up specific contextual expertise on demand. Claude Code and Cowork are enormous advancements over basic chat interfaces on this frontier.
“The Instructions”: Progress in user input and skill. I.e., how a person actually tries to explain their request to an LLM -- in terms of descriptiveness and process described in their original request, how they intervene for setbacks/revisions, and what baseline material references they point the LLM to.
Each piece is necessary, but would alone be insufficient to attain any kind of success here
Let me try and explain why these two other dimensions matter so much and what this all means together using a physical robotics metaphor. To wildly oversimplify it, imagine that you have a super-intelligent humanoid robot assistant in front of you, willing to do whatever it is you could possibly ask it to do. For the sake of discussion, and because I’m really fun and imaginative, let’s say that I want it to fold my laundry.
If I give this super-intelligent robot a comprehensive tutorial of how to fold each and every piece of my laundry step-by-step (great instructions), but it only has simple Lego-style straight arms and claw hands (incapable body), it is still going to utterly fail at folding my laundry.
Conversely, if this super-intelligent robot now has perfect human-like hands (capable body), but I just say, “Get to work!” while in another room without any further clarification at all (vague instructions) -- it’s probably not going to infer that I specifically want it to fold my laundry and fail at the intended task.
In this example, even if we have super-intelligence fixed, having even one other failing core component (incapable body or vague instructions) utterly crushes the chances of getting anything useful out of our robot friend. Each piece is necessary, but would alone be insufficient to attain any kind of success here.
This, I think, is the state of things with the AI/LLM assistants of today, and why people are so at odds about what AI/LLM assistants can and cannot do. To draw it out:
If I have Opus 4.6 (great mind; one of the most capable models ever) try to summarize a new academic paper for me, but I don’t actually let it search the internet to find the paper I’m talking about (incapable body, no tool calls)… it’s more likely to desperately make something up from its fuzzy general “memory”, and I’m going to think it’s actually quite dumb and unreliable.
If I have Opus 4.6 (great mind) working within Claude Code with access to the full library of all great poetry ever written (capable body), but I don’t actually tell it what kind of poets or poems I want to draw on for inspiration and why (bad instructions)… well, the odds that I eventually get a love poem I actually like out of that process are quite low.
In both cases, the media hype for Opus 4.6 land plainly false if not outright manipulative -- which would be fair given my experiences with it.
Wait, does this mean you’re saying I’m the problem here? The AI hype train is real?! Well, not exactly, because…
Everything is just way weirder than you think
So the far extremes are painfully obvious about ramifications, but to be clear: there’s a whole world of range within the “Body” and the “Instructions” dimensions that are far from a simple bad-versus-good binary. And what makes this even more complex is that what we even think is bad, good, better, and phenomenal on these two dimensions (body/instructions), are constantly shifting and changing day to day and even model release to model release. Getting better output out of an LLM is not nearly as straightforward as we might think; these things are way weirder and more idiosyncratic than that. For example:
Best practices on frameworks/tooling (Body) are generally coalescing towards the idea that we want to give LLMs sufficient context to do a task… but also, it seems like there are a lot of ways to provide fundamental context to the LLM that end up making the LLM perform worse than providing no context at all. Why???
It seems intuitive that providing thorough, comprehensive and well-structured prompts (Instructions) will produce better output from the LLM… but also, Anthropic now specifically recommend against being too thorough in your instructions because our instructions can actually be worse than Opus 4.6’s improvised plans for completing certain tasks. Oh…?
It stands to reason that providing repetitive, redundant instructions in your prompt would cause issues for the LLM (Instructions)… but also, just copying-and-pasting your prompt twice in a row seems to uniformly increase many models’ performance. ?!?
One of the superpowers of more refined AI agent platforms like Claude Code, Claude Cowork, Codex, and Antigravity is the ability to let the agent search over and reference a ton of different files (Body)… but also, if your documents are in PDF format instead of Markdown format, it might fundamentally misunderstand your documents and/or fully hallucinate content because it got confused during the file-read. Oye…
And we don’t even really know which of the above apply equally to Opus 4.6 versus Opus 4.5, let alone Opus 4.6 versus Codex 5.3. It’s absolute madness.
But for now, let’s just hold fixed the models themselves. Even in that state, what exactly it means to take best advantage of them via the frameworks and tooling and user prompting is extremely confusing and unclear and constantly developing. It’s hard enough to know how to talk to Claude -- how do you tell Claude how to talk to the subagent Claudes it launches? What does it mean when the subagents can now talk to each other? Getting the most out of the current frontier of AI models now means something totally and completely different than it did in October of 2025 because of these quickly fractalizing new complexities in orchestration and context management. There are just so many dimensions to optimizing the frameworks/tooling and user prompting side of things that people are simply not aware of nor privy to, and I cannot emphasize enough how quickly that field is developing as people are experimenting and learning more and more.
The information gradient drives the hype gradient
And it still gets weirder. This experimentation and skill-sharing is richest in random circles online as people report back field notes from their own varied experiences -- reddit forums, X threads, and GitHub repositories -- and the true frontier of best practice is no longer being generated by the traditional experts in this space. It’s coming from people who are tinkering on the weekends, pushing Claude Code into weird use cases and extremes, engaging in wildly extended 12-agent coding sessions with Codex, setting up OpenClaw to vibe-code away every problem in their life via WhatsApp, or letting Claude Cowork blast through producing slide deck after slide deck for a month’s worth of sales meetings.
This is why I think it’s been anyone’s game since Opus 4.5 launched in November; information is power in this paradigm because it produces extreme capability gradients from one person to the next. Foot_sniffer6467 on Reddit got to be king for a week back in January because they spontaneously uncovered an early way to get subagents to communicate on tasks synchronously while vibe-coding their first SaaS app (joke example, but versions of this are literally happening every day now).
So when it comes to the question of: What can AI do right now? It depends so completely on how much you’ve been paying attention to these weird developments in the space that fundamentally change your intuition for what you think good prompting means, and what the best practices are for helping Claude Code cook on a codebase, and etc. etc. Thus, what kind of output you’re really getting when you interact with LLMs today, and what you think is currently possible with AI, hinges accordingly. The range of inputs is enormous, so the range of outputs is now similarly enormous -- on one end, we’re seeing “Oh LLMs are too dumb to understand you need to bring your car to use a carwash”, and on the other end, we’re seeing LLMs make my PhD and years of data science experience feel less useful by the day. Almost everything in the space of Body/Instructions has changed in the last four months; blink and you have absolutely missed it.
What can AI do right now?… The range of inputs is enormous, so the range of outputs is now similarly enormous
This was one of the strangest and most disorienting experiences of working on DAAF in basically complete isolation until launching two weeks ago: as I got better and better at understanding how to work with Claude Code and all its idiosyncrasies over the course of a month (what the hell is a “Contract?” What do you mean I need to write an “Invocation pattern” for each subagent? Why do we keep calling things “Gates”???), I was suddenly seeing such a WILDLY different frontier for AI capability than anyone else I was talking to. There’s just no way that the average person casually asking Gemini to do deep research for their upcoming trip to Japan would think something like DAAF is remotely possible, and I absolutely do not blame them.
Okay, so, then… where are we really right now with AI progress?
Going back to the original two camps (pro-AI hype grifters and anti-AI luddites), I find myself uncomfortably more aligned with the AI hype grifters. As we unlock more understandings in the frameworks and tooling layer (Body), and as we individually advance on best practices for prompting (Instructions), we are unlocking multiplicatively more and more value out of the models in front of us. Meanwhile, advancements in the Body/Instructions are now directly contributing to faster improvements on the model frontier (Mind) with OpenAI's Codex famously accelerating its own development. These new models, in turn, will unlock more capabilities and frontiers for the Body/Instructions to advance; this flywheel is spinning, and it will only spin more aggressively from here. Based on how truly wild the last four months since Opus 4.5 alone have been for Body/Instructions, we are, I think, firmly in the “exponential” progress phase that people have been predicting.
That being said, I still think the AI-detractors are a particular flavor of correct, but perhaps for a reason they themselves won’t love: improvements in the frameworks and tooling (Body) and prompting (Instructions) are currently still too weird and confusing for the general public to get sufficiently good AI output quality on any sufficiently useful/complex task. I have been doing almost nothing but try to keep on top of this frontier over the past three months, and I still barely feel like I can synthesize what’s going on at any one time.
And as mentioned earlier: we can have the best AI models (Mind) out there in the world, but if everyone in the world remains, on average, terrible at prompting, we’re not really going to see the mass transformation of society that AI hypers are dreaming of and doomsaying about on the timelines they imagine. Of course, this is going to be an active field of development and progress of its own (i.e., how do we make it more frictionless to be great with LLMs? It is likely at least partially solvable), but I think the AI-hypers drastically underestimate how much inertia will need to be overcome to really start moving the needle on that overall user skill market (at least partially informed by my past life as a high school English teacher; teaching is very hard). They might argue the luddites don’t need to get on board for their jobs to nonetheless be automated away. I’m not so sure about that -- and until then, the true current frontier capabilities of AI that I and others are playing with might as well not exist to the vast majority of society.
What should I do from here? Use the mental model as a guide
I think one thing is extremely clear to me: People who can take advantage of the information gradients of this strange in-between time for AI adoption stand to gain an immense amount personally and professionally, whether we like it or not. Put a different way: I don’t think that there’s any benefit whatsoever to remaining tied the narrative that AI is/will be useless and all of this buzz is driven by self-interested hype. If you stay in that camp, you risk willfully missing a boat that doesn’t need to be missed, and it will get harder and harder to catch up as the frontiers of AI Body/Instructions best practices develop into more and more obtuse areas of literature. This is why I’ve put so much energy into education around DAAF (and this post, as one example!) -- it’s not enough, in my mind, to give people nifty AI tools they can use. They need to understand how to catch up and how to push ahead on their own. Teach a man to fish, sort of thing.
So what does that look like? Ultimately, my big brain plan here is that if you understand this Mind-Body-Instructions mental model, you already have a clear schematic for how to push your own AI output quality upward from here.
Start by building your prompting skill and intuition (Instructions): push yourself to use these assistants however you can. When it’s convenient, and when it’s not convenient. Understand their failure modes, and see if you can talk through them to find mitigation strategies. Pay attention to how your responses and the specific types of phrases you use shift its behavior. Be deliberate in testing out different communication styles and tones and vocabularies. Understand what seems to correlate with success, and test your understanding to really see if that correlation holds under different circumstances with different tasks or different models.
Then, start pushing on the frontiers of more advanced frameworks/tooling (Body): take the plunge into using something more comprehensive like Claude Cowork or Claude Code (personal bias: I really did design DAAF to be one of the fastest and safest ways to get started with Claude Code for newcomers!!). Once you’re in, start asking Claude how to get better at using Claude Code. Ask it exactly how and why Claude Code is different and more capable than the basic web chat interfaces by having it research its own online documentation materials. Get it to search online in these weird GitHub/Reddit/X communities for emerging best practices as of March 2026. Tell it to launch a subagent to do X or Y web search that informs a follow-up subagent’s task to do Z, and watch what gets communicated back and forth to you and between the agents. Point it to some big fancy repository you find from folks like Chris Blattman or new Claude Code product feature announcements from Boris Cherny and ask Claude what these things do, why they might be valuable, and how you might incorporate them into your own workflows. Use Claude to make your own skill-building Skill, and make new Skills inspired by others or tasks you actually do day-to-day. Your goal is to get better at harnessing these frameworks and tools to your own ends -- use whatever scaffolding and information you can find to that end, especially Claude itself.
The models (Mind) will progress forward inexorably from here, and people who cultivate their skills on Body/Instructions are going to reap more and more benefits from those advancements relative to people not pushing at all. I don’t want to sound like that other really dramatic guy about something big happening, but I don’t think he’s wrong. It feels like a really pivotal time, and I’m hoping we can get as many good, thoughtful people armed with the critical awareness and skills they need to flourish in this weird future as possible.
There’s much more to say, but that’s all I think makes sense to try and fit into one already very long post. I hope this mental model explains the core weirdness of the current discourse to help people stop talking past each other, and I hope it moreover provides an actionable way for people to get themselves off the sidelines of this increasingly critical frontier. If you’ve found it useful from either perspective, I hope you’ll share this post with people you care about to help bring them up to speed, too.
Experiment, push into weird and uncomfortable places, ask good questions, share things freely with one another, and don’t lose sight of the ways this newfound capability can and should be used to help others.
You know where to find me if you want more ideas. Much more to come! Good luck out there, until next time.
AI has massively increased my productivity, and I work a lot on trying to get my colleagues to engage with this technology so we can get more done together. The thing I have to remind them: "It speaks as if it knows, but it doesn't." This really matters in terms of whether 1) you pick the right task for AI, and 2) whether you trust its outputs.
From Gary Marcus: "What these systems do, no more and no less, is to put together sequences of words, but without any coherent understanding of the world behind them, like foreign language Scrabble players who use English words as point-scoring tools, without any clue about what that mean." - https://garymarcus.substack.com/p/nonsense-on-stilts