
Peer review is dead; Long live peer review!
Six steps towards building a more optimistic AI-empowered future for academia and science, together


What can we be hopeful for in the age of AI?
Much is being discussed about the tectonic changes coming to academia, journal publishing, peer review, and scientific institutions writ large as a result of AI technological progress. While I don’t always agree with the fearmongering-adjacent framing of some of these articles, I think their urgency and the conversations they’re starting are absolutely necessary given the rapid rate of progress; it really does feel like you’ll find yourself falling behind if you so much as blink lately.
It’s maybe no surprise then that many articles in this conversation to date have been focused on what you stand to lose if you don’t get on board, especially if things continue as unchecked and uncontrolled as they currently feel. I’d like to add to this conversation by instead presenting what I think we collectively stand to gain, and the brighter future we can all collaboratively push towards, if we keep a crystal clear focus on our core values and our actual purpose as a scientific community.
To that end, I’m going to describe a roadmap of six concrete steps we can push towards that together could unlock a more hopeful AI-empowered research paradigm: one where we can rigorously deepen, refine, share, revise, and make actionable our collective understanding of the world at a pace that we can barely even dream of today. One that sheds many of the deeply-entrenched issues with our existing scientific and academic processes while allowing us to bring rigorous new knowledge to the people who could use it most at near-lightspeed. One where genuine scientific inquiry can finally match the pace of and combat the misinformation crisis spurred deeper by this very same AI revolution.
At the risk of sounding overly optimistic, I believe you’ll see a place for yourself in this scientific community of the future -- because I believe this new paradigm will make the expertise that you’ve cultivated in yourself and others more valuable than it has ever been for society and our progress as a civilization.
If you are reading this, I want to emphasize that you are not a passive observer in these branching pathways yet to come -- you can help us get there.
Importantly, I am not attempting to predict some likely future, but instead trying to envision one possible future that should excite you rather than frighten you. And if you are reading this, I want to emphasize that you are not a passive observer in these branching pathways yet to come -- you can help us get there. My hope is to call colleagues to action to be a part of this conversation, and moreover spur critical alignment in the scientific community to set high standards and expectations for anyone seeking to disrupt the broader research ecosystem with AI in this age of grifters and opportunists.
To be clear, you really need to be skeptical of anyone just vibing out with big crazy ideas about AI right now. I’ve been thinking about machine learning and data science methodologies for social science since about 2018 as a grad student, and went on to finish my Ph.D. dissertation largely focused on developing careful ways to apply LLM-related methodologies to education data back in 2022. I’ve continued to work on that frontier inside and outside of academia ever since, and more recently, I have been working basically non-stop since December developing what I see as one stab at the pivotal first step on this roadmap (more on that in a second). You should definitely still take everything I’m saying with an enormously large grain of salt. These are big speculations that need be interrogated by people with more varied perspectives and areas of expertise (especially those outside the social sciences!). Please bring your ideas, and absolutely push back and be critical of myself and any others entering this arena.
This is a big one, so with that context and preamble, let’s get started.
Table of Contents
Building the foundation
Creating the new paradigm
Building the foundation
Step 1. AI-empowered research tooling: AI allows us to rapidly accelerate the production of many scientific claims, and we must center transparency and reproducibility as core requirements
With the advent of Claude Opus 4.5 in November, we’ve seen an absolute explosion in the rate of capability progression for AI across domains. What does this look like in the broader field of scientific research, and how do we manage the inherent risks?
Where we are today
Skepticism about this is absolutely warranted, but I do think that on balance, we will continue to see rapidly expanding value for using AI to accelerate research pipelines on multiple frontiers when applied rigorously and carefully (if you find yourself highly doubtful of the possibilities here, I recommend my companion piece on why no one can agree on AI progress right now).
For now, we should expect that this sort of progress is jagged but inexorable: some domains of work can have large chunks of their research pipeline drastically accelerated today (e.g., quantitative data analysis using publicly available data), while others are going to see less of their work conducive to this degree of acceleration for longer (e.g., field work, archival studies, qualitative interviewing, etc. Also highly dependent on context-specific data protections/privacy, legal and bureaucratic restrictions, etc.). Think of this as realistically the piecemeal acceleration of specific tasks with varying degrees of improved efficiency, rather than wholesale automation (which I think we should be extremely skeptical of!). The human effort/time saved from tasks that can be accelerated gets refocused on tasks that cannot.
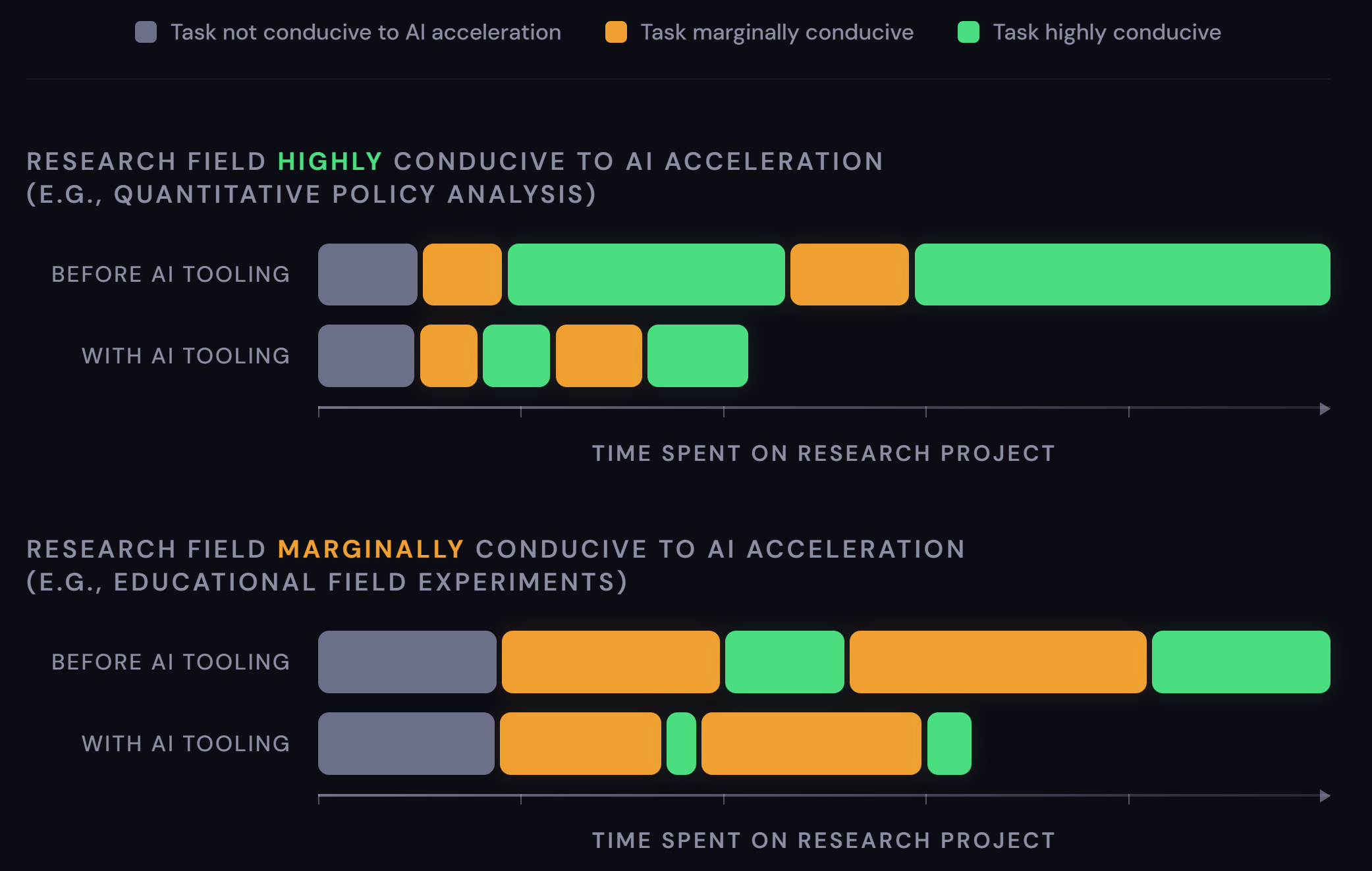
People are today broadly experimenting publicly and privately, producing tools and frameworks of all kinds across disciplines for people to test, react to, share, and build on as awareness of AI-assisted opportunities grow. In the meantime, there’s a lot of promise, a lot of worry, a lot of variability in quality, and a lot of disagreement.
Where we need to go
The rate of production for research claims on those frontiers initially more amenable to AI acceleration will increase at first steadily (initial tooling uptake) and then exponentially (broad tooling advancement interacting multiplicatively with frontier model advancement). At the same time, quality of research becomes substantially more variable: from outright hollow slop to novel new research that expands far past what was previously ever feasible. The former is inevitably orders of magnitude more common relative to the latter. As these advancements continue, more tasks will become amenable to AI acceleration, and more fields will begin joining that rollercoaster of trying to navigate the growing quagmire.
Left unchecked, this would begin part of the academic death spiral that people are concerned about: Research production (with increasingly wide variation in quality) is likely to scale significantly faster than existing systems can filter and review it, causing major bottleneck issues for the publishing pipeline. We simply will not have enough reviewers or expert time to go around, quality and timeliness across the board will suffer, and trust in our institutions will wane.
With that in mind, we cannot leave this unchecked.
Transparency and reproducibility need to become core requirements for any and all research produced with AI assistance. As a scientific community, we need to align on these standards and practices immediately by setting strict norms and expectations for both tool creators and users. This buys us four key victories in the short term:
LLM-based AI will always be susceptible to hallucinations; enforcing true transparency and reproducibility will both stem the tide of low-quality slop being produced (since users can better self-verify) and make it far easier to assess and hold people accountable for their work in the current systems (since this immediately supports efficiency for current review systems).
By enforcing auditability in all AI systems, we improve our collective ability to learn more about their current failure states, appropriate and inappropriate uses, and exactly how to harness them more effectively going forward as a scientific community. Our intuition for using these tools well will improve commensurately.
With greater auditability, we also improve AI’s own ability to self-monitor, self-correct, and self-improve iteratively. This allows us to automate the enforcement of higher levels of rigor for anything coming out of these systems (but, importantly, still cannot eliminate hallucinations).
Stricter alignment around the standards we hold for AI tools and frameworks will allow us to demand and develop higher-quality tools, sooner, further reducing the issue of slop per se while pushing the capability frontier past this informal/awkward experimentation phase.
This era of LLM-based AI really feels as if someone’s just dropped a series of power tools into the middle of a playground; every minute that goes by without someone stepping forward with actual recommendations for responsible use invites more and more potential collateral damage in the form of misinformation and pseudoscience. Even worse, it deepens misunderstandings and disagreements about how these AI tools can and should bring value to our disciplines, because there are dangerous AI tools being peddled to the public in the same venues as legitimately useful and careful AI tools.
Many AI-empowered research tools already exist today, and they are collectively the worst they will ever be.
This urgency is exactly why I have spent so much effort developing DAAF fully open-source (forever free, I promise I am not trying to sell you anything!) with enormous amounts of explanatory materials (perhaps to a fault) -- it is equal parts AI-empowered research tool useful for accelerating many quantitative data analyses right now, and genuine philosophical missive trying to firmly establish these standards of transparency, rigor, and reproducibility in practice for others to react to and iterate on. I don’t know if what I’ve put together is the full set of everything we need, but it’s at the very least a strong and useful starting point for the discussion.

Whether or not DAAF becomes a tool the research community uses more broadly, we collectively need to have this conversation and establish a minimum bar for what we can and should be demanding of people attempting to develop tools and disrupt in this space. These standards need to then also be applied consistently and vocally to users as well. We cannot accept anything less than full reproducibility and auditability from researchers leveraging AI tooling in their work; we must hold each other accountable to high standards of rigor and responsibility as peer researchers as we always do. To facilitate that accountability, we also need to redefine academic honesty to include proactive AI tool use disclosure.
These norms, together, can drastically reduce the chaos and harms of this experimental/exploratory phase of AI tooling uptake. Institutions, journals, professional organizations, and grant-funders must collectively lead the way here across communities as quickly as possible; this work can and should begin now.
Looking ahead: many AI-empowered research tools already exist today, and they are collectively the worst they will ever be. Even if we align around the stringent requirements of transparency, rigor, and reproducibility, the massive spike in research production facilitated by this tooling will still ultimately continue to accelerate and broaden across tasks/fields until our traditional systems for research review and publication choke.
Step 2. AI-empowered reproducibility verification: AI allows us to rapidly verify the mechanical reproducibility of many claims, and we must modernize journals accordingly
If better tooling will make it nigh costless for a researcher to produce enormous variations of analyses using the vast libraries of available public datasets (alone and in combination with one another), how could our current systems possibly keep pace?
Where we are today
Step 2 hopefully makes obvious the necessity of centering reproducibility in Step 1. If novel analyses facilitated by AI are, by design and by default, always required to be fully reproducible (which becomes a powerful initial filter for journals to use on its own), then it becomes trivial to also facilitate the mechanical verification of any submitted research results accelerated with AI. This will ultimately serve as the next line of defense against full-on waves of AI slop research. And to be clear, this is not hypothetical: the early stages of this systematizing are happening right now with researchers building tools to formally and fully verify the reproducibility of research results at scale.


This core requirement of reproducibility allows us to immediately and automatically answer the question of, “are we able to replicate this set of findings?” But we can actually go one enormous step further: we can automatically verify the full, reasonable possibility space of statistical specifications for a given analysis and thoroughly investigate robustness and alternative analyses as a matter of course. In this future where the marginal cost of exploring an alternative specification is nearly zero for both the authors and the reviewers, p-hacking may very well become a thing of the past. This is also not hypothetical; we have an open-source approach for this style of work today, released literally as I was writing this post:

Where we need to go
These types of tools together, when combined with a standard of strict reproducibility for all AI-empowered research, are what will give our existing systems a fighting chance in the near-term. The community alignment around tooling produced in Step 1 should meaningfully reduce, but cannot eliminate, the amount of slop making its way to the doors of journals (i.e., by improving the standards of production); the tools surfaced here in Step 2 then facilitate enhanced filtering through the massively expanded inflows of research submissions while maintaining a strong level of quality -- perhaps even higher than it would be otherwise.
While these proofs of concept give us a hopeful start, it’s a completely different ballgame to operationalize these expectations and verification processes at scale where the work actually happens. Most journals, academic institutions, conferences, and research institutions seem woefully underprepared for navigating the initial conversation about AI-empowered research tooling (Step 1), let alone the downstream need to receive said research products in equal AI-empowered measure.
This is an arms race with the quality and sustainability of our research publications at stake. Those who are able to influence these entities to modernize and build appropriate infrastructure should be doing everything they can right now to start moving that machinery even if still imperfect; this is admittedly far outside of my experience or wheelhouse, so I’ll have to let others provide more insight into what that might look like (see, e.g., Scott Cunningham’s “A Modest Proposal for Editors” post). But I suspect there are a lot of very difficult conversations to be had here around incentives, institutional inertia, prestige signaling, academic politics, and funding.
Step 3. AI-empowered validity assessment: AI allows us to rapidly critique the appropriateness and rigor of a given claim, and we must make these tools broadly and freely accessible
Now even if we can get things moving on that automation front, verifying reproducibility and building in safeguards against p-hacking are not the same as assessing empirical rigor and validity. How can we address that more directly?
Where we are today
Alongside Steps 1 and 2, this Step is the third foundational pillar on which the rest of this roadmap relies. We know that research is not just some simple data-in-statistic-out pipeline of truth; it is critical to understand the nuances of the data, build on what we’ve learned in the past, recognize the necessity of different methodological approaches, and be thorough and thoughtful about what interpretations or conclusions are actually supported by the given results/analyses. Something can be technically reproducible while flying in the face of all of these fundamental tenets of good science; while reproducibility is necessary, it is alone insufficient. We need to be able to also assess rigor and validity at scale.
You’ve probably caught on by now: we’ve already got multiple private (1 and 2) and open-source projects on the market today designed to help scale and automate peer review with AI assistance. Yet another open-source project was also posted as I was drafting this (I swear I’m writing as fast as I can!!):



If you’ve ever been burned by an unfair/unqualified/vindictive/generally-grumpy human reviewer (and who hasn’t?), you probably wouldn’t fight the claim that these AI reviewers will quickly be able to do a better job along certain vectors than some human reviewers (interesting new benchmark from one of the private options, Reviewer 3, here). And with far more favorable turn-around times! Based on some of the recent high-profile public praise for Refine.ink, there’s no reason to think this quality frontier won’t continue to advance quickly and present meaningful value-add for more and more fields across the board.
There is ample discussion today about how best to leverage these tools, with a lot of possibilities on the table. Do journals operationalize a low-bar AI review as a pre-filter before human peer review? Do journals employ an AI reviewer as a third/fourth reviewer in tandem with the typical human reviewers? Do we use AI reviewers to contextualize/refine/summarize the reviews of human reviewers?
Where we need to go
Yes, journals should be exploring these steps, and I’d also suggest that there’s an especially enormous value-add for pre-print archives like arXiv to begin incorporating automated reviewing (not necessarily as a filter, but as a contextualizing companion for posted articles). Making these tools better, more comprehensive, more aligned with scientific judgment and best practices, and free will be absolutely critical to any future for research.
But I ultimately do not think AI-assisted peer review is sufficient to handle the coming tide of AI-accelerated research production beyond the very short-term, even with the reproducibility requirements (Step 1) and verification filters (Step 2) in place. There needs to be a much more meaningful shift in how we conceptualize the role of the journal and of research publication writ large.
Peer review is only one way to reach the actual goal of maintaining high research quality… I would also argue that peer review is often actually insufficient at accomplishing this goal.
In the current academic system, keep in mind that peer review is only one way to reach the actual goal of maintaining high research quality and ensuring that a finding is situated in its proper context/hedging/cautions. I would also argue that peer review is often actually insufficient at accomplishing this goal. Great journals have a roster of great reviewers that assure higher consistency, but a paper’s ultimate standing after peer review is at least partially a function of who the editor is, who the reviewers are, and (given how rarely peer review is truly blinded in a world with increasingly common pre-print sharing and small conference circuits) the authors themselves. Far, far from a purely objective quality function.
Moreover, the current system for peer review often entirely obscures the revision process alongside any concerns that were left unaddressed regardless of their validity -- especially if a paper was shopped around to multiple journals with multiple rounds of disconnected peer review. Forget the fact that the average lay person has no idea about the hierarchy of journal quality for a given field, so “peer reviewed” is a noisy and often ill-applied indicator of research reliability even in the best of times.
All to say: If the true goal is to help end-consumers of research insights understand what research we can/should trust and how to reasonably apply it, attempting to simply band-aid over an already breaking peer review system seems like a fool’s errand.
So what comes next? Systems-level augmentation.
Creating the new paradigm
Step 4. AI-empowered research dissemination: leverage AI to rapidly disseminate a wider variety of rigorous, reproducible, and validity-assessed claims to the public when and where it’s most relevant
We need something far more drastic for a long-term response to fix the publishing game. Steps 4, 5, and 6 together represent my hope for what comes next; we’re getting much more speculative from here, so buckle up and ready your healthy skepticism.
Zooming out for a second, Steps 1, 2, and 3 taken to their logical ends will give rise to a research production environment where:
Researchers can produce a basically limitless array of quantitative claims using publicly available data, almost instantaneously and costlessly
Said claims can likewise be almost instantaneously and costlessly checked for reproducibility, examined within the full possibility space of alternative specifications, and then contextualized with automated assessments for appropriateness and methodological rigor
You might say, “Well, this is going to be true for simple descriptive statistics, but it certainly won’t be true for highly complex causal or theoretical or qualitative or [x] work.” A bigger question to untangle, but I’ll grant it: we need only scope to simple descriptive statistics from public data for now anyway. I’d argue that the vast majority of scientific insight is reflected in these simple, descriptive, atomic claims, because underpinning any sufficiently complex paper with causal merit or new theoretical frameworks or [x] are hundreds (even thousands?) of these atomic descriptives.
I’d argue, if anything, we are actively destroying an immense amount of value to the public through current review systems.
And for said atomic descriptive statistics, how much value is actually added by human reviewers and the explicit approval of a given high-profile journal? I’d argue, if anything, we are actively destroying an immense amount of value to the public through current review systems.
Think: how many of these atomic statistics are rendered fundamentally inaccessible and unactionable to the public by burying them, as we currently do, in tables and appendices and figures and footnotes and motivation -- all in service to a single fancy, well-identified causal statistic? E.g., how many valuable year-by-year state level metrics are buried in any given difference-in-differences analysis? How many useful distributional facts about a running variable are lost to the appendices of a regression discontinuity paper? What golden insights about implementation fidelity and sample attrition are hidden in the robustness checks of a good field experiment?
And how many authors have been told their causal merit was found lacking, resulting in these hundreds of perfectly good and useful atomic statistics never once seeing the light of day? How many low-hanging descriptive projects have never even gotten off the ground because authors know well enough not to waste their time or resources on something that’s not going to be perceived by journals as “rigorous” or “impactful” or “relevant”? Think of how many such atomic descriptive stats have helped us understand our world and society but would never get published in an academic journal because they’re too simple (e.g., the vast majority of U.S. counties had higher republican vote shares in the 2024 presidential election versus 2020, one of my all-time favorite data visualizations).
How much useful knowledge are we leaving on the table? And for what?
Split the publication pipeline
If tasks that can be accelerated with AI will allow humans to shift their focus to tasks that cannot, our institutions should optimize similarly; we will all be far better for it.
That in mind, I think we’ll soon arrive at a new equilibrium with two separate pipelines for knowledge production and curation: one for the set of atomic, verifiable claims that we can produce at scale, and another for basically anything else that’s not conducive to the scaling/automation of the first. For now, let’s focus on that first pipeline; Step 5 will focus on the second.
With the tools available today, and certainly with the tools available a year or two from now, I envision an “open knowledge repository” for research publication where:
Researchers submit their atomic claims and code to a public repository of knowledge, wherein every single claim is subjected to the standard protocols of reproducibility verification and validity assessment.
Said claims, once processed and ingested, can be situated in a vast knowledge graph linking it to related claims by topic, data source, methodology, findings, implications, and more.
Users can query this repository like a modern-day oracle for any research question, any topic of discussion, and any issue of the moment.
On a query, the repository will trace the knowledge graph to automatically surface relevant atomic claims situated within the context and hedging and caveats tagged by the automated validity assessments, and interpreted accordingly.
Said interpretation/synthesis will be frictionlessly and costlessly subjected to the same rigorous validity assessments as the underlying statistics themselves.
Every atomic statistic “node” generates a public tracelog for every time it is referenced by the querying system to better track usage and public utility.
Repository systems actively scan and track mentions of specific statistics across news outlets, policy briefs and documents, and social media discussions to track the downstream use of any given statistic -- as well as the utility of upstream data sources, foundational literature, underlying methodologies, and more.
Repository stewards facilitate highly accessible querying via multiple means. The same way X users can frictionlessly tag Grok to invoke general AI assistance (e.g., “@Grok tell me what this means” for better and for worse), repository stewards make the system queryable broadly where the conversations are actually happening and related decisions are actually being made on a policy and personal level.
Combined, this system allows for lightning fast knowledge generation and iteration on an honestly enormous number of frontiers, trackable metrics of genuine societal value and impact to help incentivize researchers producing inputs to said statistics, and the potential to intervene on and combat misinformation across public discourse more broadly. Fundamentally, this system democratizes access to and use of rigorous, verifiable information and scientific insights in a way that no iteration of our current system would ever come close to accomplishing on its own.
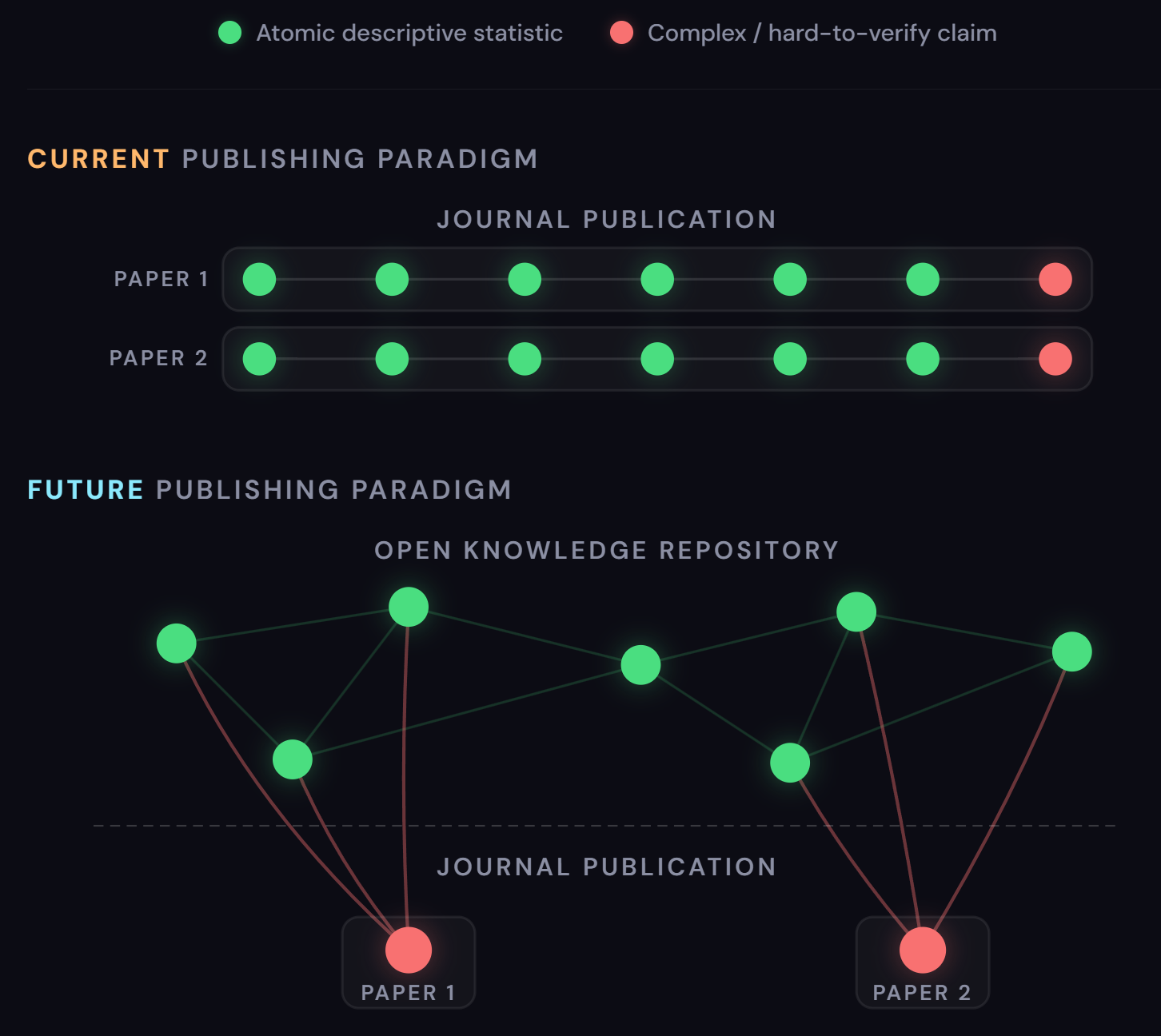
Who will build this? It’s the right question, and while I think I see the ingredients of this sprinkled across the community already, this is absolutely no trivial undertaking. A project like this necessitates working through exceptionally difficult and complex questions about governance, attribution, incentives, adversarial gaming, defining rigor, iterative revision, and dispute adjudication. For now, call it a wish, but I suspect many will agree on the necessity of it given the future we’re heading towards. If the community can align here, I think the leaders and contributors will surface accordingly.
Step 5. Human expertise where it is needed most: Refocus trusted academic institutions on becoming hubs of verification for complex research insights and research using private data sources
So that said, what of the journals?
To be clear, this open knowledge repository is scoped to be intentionally narrow in two ways. First, it only works for sufficiently atomic claims conducive to automated reproducibility verification and validity assessment. Second, it only works for claims that can be verified using publicly available data. Neither of these are trivial limitations.
The current journal publication system thus stands to gain an immense amount by quickly refocusing their efforts towards specializing in these two arenas.
By offloading the brunt of AI-accelerated claims and studies to the automation of the open knowledge repository, the existing institution of peer review is given a new lease on life. Qualitative work, theoretical contributions, more complex methodological developments, historical perspectives and syntheses -- anything that cannot be mechanically verified still has a home in the journal publication space where some version of peer review and more intensive/manual vetting for contribution and quality still exist.
Moreover, the existence of this open knowledge repository actually makes the task of reviewing certain complex research insights more tractable as well. For example, rather than ask reviewers to assess and pore over a multi-staged argument with layers of atomic descriptive statistics and prior literature (which each may have their own issues with data provenance, sourcing, rigor, etc.) building towards the argument of validity for a single unique argument/claim, those atomic descriptive statistics and accompanying verifications can now just be referenced as a simple matter of public record. The reviewing focuses entirely on validating a paper’s unique argument and contribution in context to speed up and simplify the peer review task considerably. In this and many other ways, I expect the format and scope of the academic paper will be amenable to quite a bit more streamlining in this future.
These AI-empowered verification tools become completely ineffective in the face of privacy-protected or proprietary data that otherwise can’t be shared.
As for the other key problem for journals and institutions to tackle, consider that the mechanical verification and assessment of research as discussed works only insofar as the datasets used to produce them are themselves valid and trustworthy. The potential for data manipulation throws all the confidence produced by reproducibility and anti-p-hacking and validity assessments out the window, which means that these AI-empowered tools become completely ineffective in the face of privacy-protected or proprietary data that otherwise can’t be shared.
This is where our existing journal publications and institutions can leverage their legal resources and reputational trust to great effect. Journals can engage in highly restrictive and protective data use agreements with researchers leveraging private data sources for the strict purposes of data validation and then downstream research insight reproduction/validation, in a way that is simply not feasible for a public repository on multiple levels.
This enables them to serve as the sole verifiers and validators for any research with these datasets, cordoning off valuable insights under their banner and brand. If we think of the open knowledge repository as the core layer and foundation of research insights, an individual journal can then present a distinct extension layer on top of it. Said journal would produce their own knowledge graph populated with both carefully vetted and peer reviewed knowledge that isn’t conducive to automatic verification/assessment, and any knowledge derived from private datasets.
There are a lot of potential ecosystem ramifications to this two-tier system, especially when it comes to journal sustainability, public access to knowledge, public use of knowledge, and more. But I suspect journals will want to compete for the most valuable complex research insights and most uniquely valuable private data ecosystem additions -- which honestly is probably not all that far off from their current role today. The more of these net-new nodes of insight they generate on top of the existing open knowledge graph, the more viable it becomes for them to serve up their own information querying services to the public for a fee or for prestige. Journals are also highly incentivized to maintain high standards of quality and rigor to cultivate trust, such that the public respects and understands the validity of evidence from their knowledge graph despite a necessary lack of transparency.
I won’t go too far down this road, but the competition here is likely to be fierce and, ultimately, quite good for everyone. I don’t love the necessity of restricting access to enormous tranches of knowledge, but I’d argue this is still a meaningful net improvement on the nightmarish accessibility and utility issues of modern-day journals given the automated querying/synthesizing of research insights made possible here.
Step 6. Human effort where it is most valuable: Revalue rigorous data collection, robust data infrastructure, and methodological refinements as the highest-impact activities for advancing scientific knowledge
Given Steps 1-5, we will have a paradigm where one of the primary limiters to our generation of new knowledge and insight is the availability of data to analyze. And maybe most optimistically: every new data source brought into the public arena is now multiplicatively more useful. Researchers have every incentive to mine any new data for new insights as quickly as possible -- slam it up against existing public datasets, slam it up against private datasets, update earlier analyses that are now outdated, go crazy. Traversing and reporting back on the complete surface of all analyses and possible specifications is a matter of course in this new world, and that process will only happen faster and faster with the underlying improvements to core AI technology. If all of this can happen with relatively little human intervention, where does this leave the frontier of work for most human labor in the research sphere?
Data collection is a fractal: the more we gather, the more we know we don’t know.
In this new paradigm, collecting that data and sharing it out becomes one of the highest-value opportunities for any researcher, especially if the open knowledge graph allows for proper and immediate attribution to the data providers. The sexiest arenas of work in this future? Lab experiments, field experiments, new sensor/measure creation, qualitative data collection, surveying, archival data collection/aggregation, and so on. And as anyone in those fields can tell you right away, there will always be more than enough work to go around even if AI tooling on these frontiers expand. Data collection is a fractal: the more we gather, the more we know we don’t know.
This is, I hope, how we transcend the “looking for your keys under the lamppost” problem inherent in today’s work. When collecting new data is so strongly incentivized because of its readily attributable value and impact, what does that unlock for us in terms of valuing data collection for new populations, geographies, topics, and approaches that our current system actively disincentivizes?
Going one step further: ensuring high quality data collection and rigorous documentation of data provenance/methodology will be seen as entirely non-negotiable. With this paradigm, the frontier of progress is not just new nodes, but also improving existing nodes (and thus all nodes that exist downstream from them). In a world where every public dataset can and will be scrutinized from every possible angle, issues and concerns will be laid bare in multiple ways and percolate downstream into substantial hedging and validation issues. Collectively, we know that garbage in = garbage out, and no efforts or expenses should be spared to ensure that the inputs of our new scientific community are as manicured and documented as possible.
To the extent that these are unavoidable, errors and issues found in data provenance will be able to percolate almost immediately through the graph, and that leaves an arena of opportunity for researchers to iterate on and update affected/stale nodes. Methodologists across the board will thus also have plenty to do, as the open knowledge graph should similarly make it easy to understand how such skills and expertise are absolutely fundamental to the downstream knowledge generated. New and better methodologies, approaches, and critiques create a similar arena of opportunity for those early appliers of said techniques to update existing nodes.
And the sexiest institutions in this future? The open knowledge graph tracing and telemetry system will finally be able to offer the immense credit and flowers long overdue to public data curators and infrastructure providers. Basically everything in this system fundamentally hinges on having open, reliable, and free access to a wide and growing array of public datasets. Someone needs to keep those lights on and keep those trains running. The value to humanity that these infrastructural entities currently provide is enormous (e.g., IES and Urban Institute in my corner of the education world), yet often go under-acknowledged despite how many hundreds or thousands of studies leverage them for critical table-setting or assumption checking along the way to their fancier statistics. Investing/reinvesting in these trusted infrastructure providers will be absolutely pivotal for this future to be at all possible.
The end of the beginning: Instantaneous knowledge generation/verification and exponential scientific advancement for the public good with all hands on deck
Researchers come at the work from all different angles, but my suspicion is that we are all aligned on wanting to marshal the skills and expertise we’ve each cultivated over many years towards helping our broader society move forward and become better for more people than it is today.
I’m hoping that the prospects presented here are genuinely exciting to you from that perspective: a world where our work can be more useful, more accessible, more expansive, more interconnected, more inclusive, and -- I’d argue -- more rigorous. An academic system that can finally grow past the many fault lines and inefficiencies and injustices we all see and recognize but can’t figure out how to resolve as of yet.
I won’t lie to you: I truly have no idea how likely this future is. I have no idea if I’ve completely misread where some of these strands and roads lead. I can’t possibly know if this new scientific community even as described will actually have a place for everyone. Writing this post has taken a lot out of me (no AI, see disclosure in the footnote!), and the endless running down of possibilities and alternative scenarios has me feeling a bit like Doctor Strange in this moment:

But I am willing to be hopeful. I am willing to strive for it. I think there is reason to look forward to what we can build, if we do so together with eyes wide open and in honest collaboration with as many people at the table as possible. The doom and gloom -- while understandable given how truly wild all of this *gestures vaguely* is -- serves as a sinister, disempowering force. But because this will almost certainly be a painful, complex, and harrowing transition even if we play all of our cards right every step of the way, we need all hands on deck. I urge you not to give in and not to check out when there is so much intensive and delicate work to go around in trying to fully realize each Step as described above.
There is infinitely more to say on all these points, and infinitely more hedging and cautions and caveats I’d like to add. But at this point, I think I just need to open the doors for others to weigh in, react, refine what I’ve pieced together here, and start thinking of more ways we can arrive at a better future -- any better future than the one it feels like most people are currently anticipating. What here feels most realistic? What feels like fantasy? What steps am I missing? Where can we iterate, and where should we start over from scratch? Is this a future you see yourself and your colleagues in? Is this a future you even want to be a part of? Where do you think you could see yourself contributing to moving us forward? And then more concretely, what does the funding model for any of this look like? What of the next generation of researchers? What about skill formation and atrophy among the current generation? What are the ethics of boiling the seas for this vision of science? How do we avoid actually deepening the existing inequities of our system in this transition? It’s all endlessly complex; I simply can’t wait to hear what ideas people bring to the table to keep this conversation moving and growing.
These questions will be hard, but our future can still be bright if we cultivate critical awareness and alignment across the scientific community, push back against the AI grifters/hype-sellers, and actively choose to make it so on our terms.
Who knows what amazing things can come after that?
Further reading: If you want to hear more elaboration from me on a few related points, you might find some of my DAAF FAQs focused on philosophical questions valuable. If you’re not sure how to start diving in with everything that’s happening in AI progress right now, I recommend my more accessible companion post on Why no one can agree about AI progress right now. I have also linked about a million articles and posts throughout this article; I think I’ve presented only a handful of unique ideas here re: academia’s future, with most of my job really just being putting others’ thoughts together into a more unified roadmap. Please do take the time to dive into what I’ve collected here from folks like Alex Imas, Emily Bender and Alex Hanna, Solomon Messing and Joshua Tucker, Andy Hall, Margaret Mitchell, Jessica Hullman, Susan Bowles Therriault, Rachel Garrett, and Kyle Fagan, Sean Westwood, Scott Cunningham, Joshua Gans, Noah Smith, Alexander Kustov, and David Yanagizawa-Drott.
Disclosure/Acknowledgments: Not a single word of this was written by AI despite my many attempts to coax something useful out of it. It was helpful in suggesting a few tonal revisions, but not remotely as helpful as many amazing colleagues who were willing to step up and help on early drafts. Sorry Claude, you’re still just not there yet! Huge thank you to Erika Tyagi, Jae Yeon Kim, Preston Magouirk, Daniel Stone, Eric Giannella, Katharine Sadowski, Amanda Lu, and Cody Sigmon for their thoughtful engagement and feedback; any remaining errors and issues are my own. Also, big shoutout to Zara Zhang for the phenomenal frontend-slides skill that facilitated all the very nice mental model graphics throughout this and my other articles!