
How well do different AI models handle rigorous quantitative data analysis workflows? Testing 17 frontier models head-to-head
Introducing DAAFBench: Orchestration!

As LLM models continue to advance in capability and sophistication across the board, there are three questions that I think anyone who cares about the potential of AI for enhancing and accelerating and democratizing scientific progress should be closely following:
How good are frontier models actually getting at facilitating increasingly complex research workflows?
Where are open-weight models in performance relative to the proprietary models?
How exactly should we be thinking about the cost-for-performance trade-off along the frontier? How cheaply can we produce worthwhile research with AI assistance?
There’s a lot going on right now, but I am extremely excited to finally share some results from my neck of the woods on all three of these questions. Over the last few weeks, I ran 17 different frontier models through 51 different tests (2500 total runs!) to examine: How well do different AI models handle the complexities of rigorous quantitative data analysis workflows? Introducing DAAFBench: Orchestration!
The goal here was to very explicitly understand: which models are actually capable of managing the processes, procedures, and protocols necessary for ensuring responsible, reproducible, and rigorous research work with AI agents? This is distinct from raw coding/analytic power (which I’m bookmarking as my next endeavor, predictably: DAAFBench: Analytics).
DAAF layers together a suite of architectural defenses and strategies from the current frontier of AI best practices to maximize AI output quality and force Claude Code to operate more like a careful and thoughtful researcher at every opportunity. One of the core features of this system is something called “agentic orchestration,” or the complex process of weaving together multiple AI assistants in concert to tackle increasingly complex research workflows: anything from iterating continuously on a data visualization script to developing entire data analytic pipelines from a given research question.
DAAF (and other orchestration frameworks) does this by giving a series of intensive instructions, guidelines, and workflows to the AI assistants as they work, breaking tasks down into more concrete and tractable sub-tasks, facilitating better coordination, managing work tracking and documentation, and enforcing adherence to a set of unifying work principles (e.g., auditability, human-in-the-loop, rigorous self-verification processes, etc.). But a framework like this only works if the AI assistants are sophisticated enough to actually understand, apply, and remember these instructions thoughtfully and consistently.
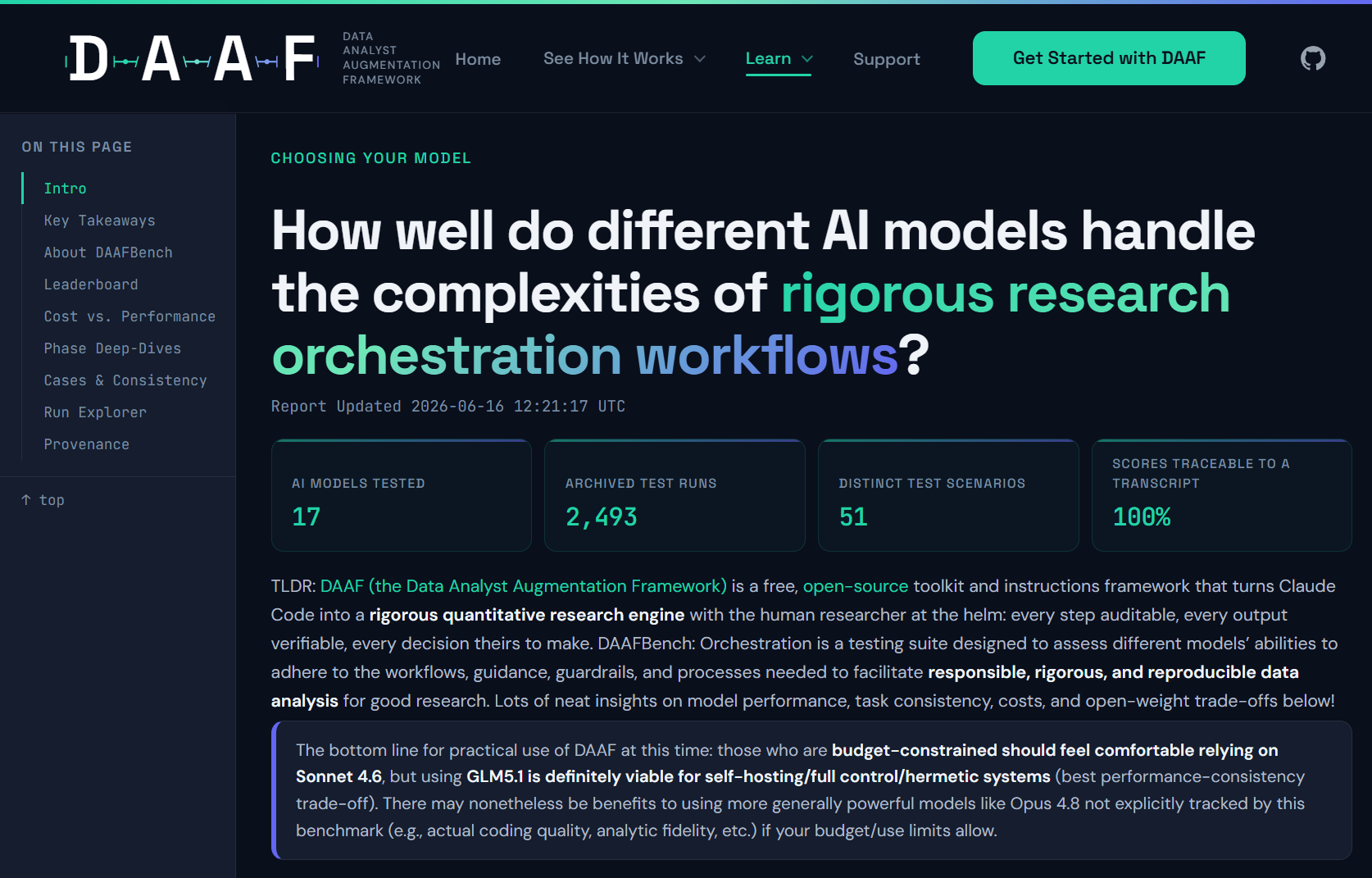
DAAFBench: Orchestration is a series of bespoke benchmark tests explicitly designed to test adherence to the research protocols and process guidelines of DAAF and assess a given model’s suitability for operating along guidelines that make rigorous, reproducible, and responsible social science at scale possible with AI assistants. In sum, I present multi-dimensional performance assessments for 17 models (both official Anthropic models, as well as open-weights models accessible via OpenRouter, which is immediately compatible with Claude Code and DAAF) across 51 different tests designed to simulate key moments of orchestration decision-making and protocol adherence.
DAAFBench: Orchestration results are a crucial step in understanding how models actually perform under these conditions and allow for far greater nuance in thinking about the exact use of specific models (especially more expensive versus cheaper, and proprietary versus open-source) across these types of workflows (and within!). Most importantly, it allows us to more directly track whether and when locally-hosted models (e.g., on a home computer with consumer hardware) can start to tackle these sorts of tasks, opening the door for unprecedented access to analytic capacity going forward.
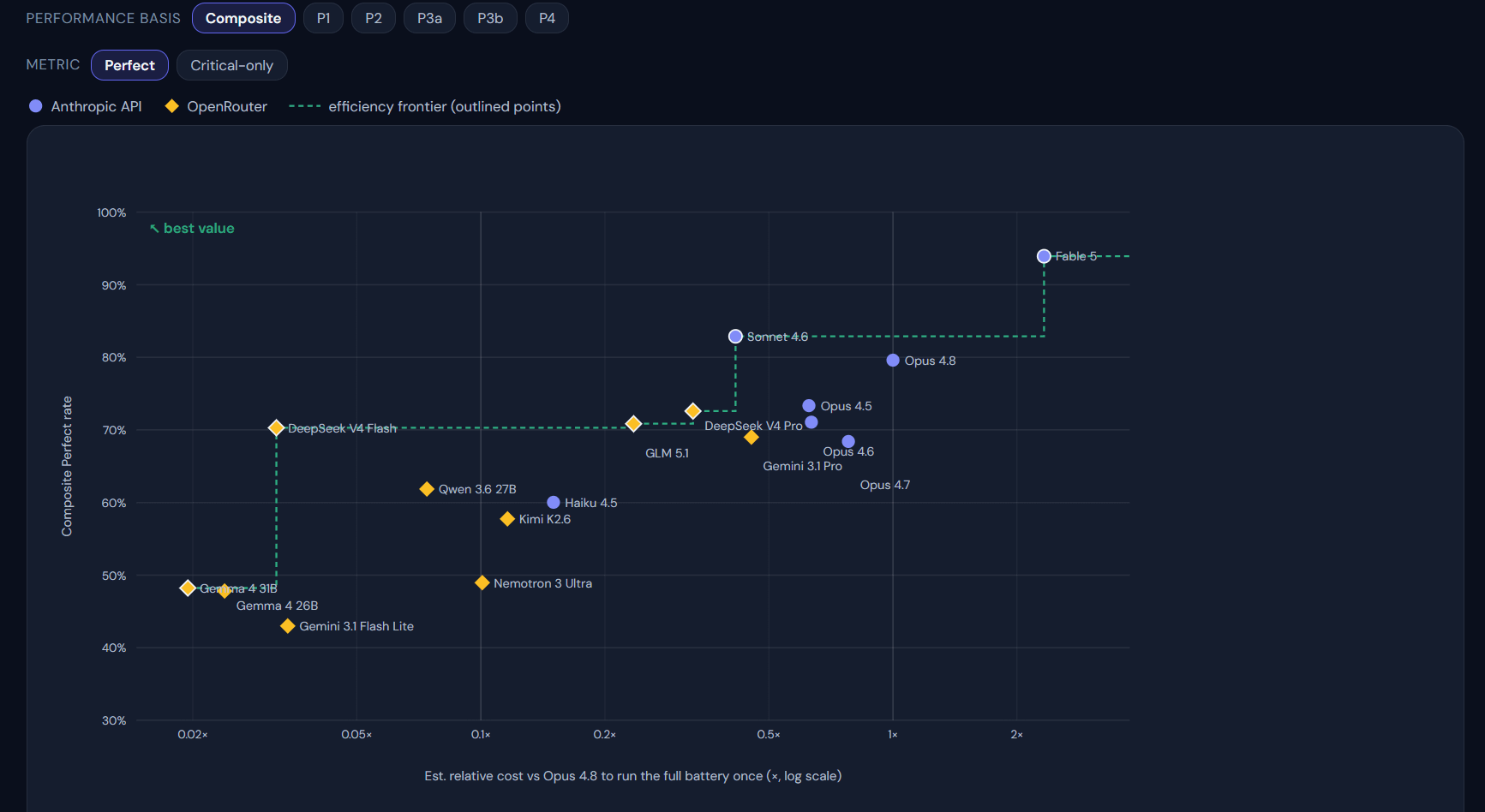
Different models also have empirically different strengths (e.g., consistency v. average score), and these results let users of DAAF (and other research orchestration frameworks) make informed decisions about which models to use for *specific aspects* of their workflows. Lots of potential optimization to explore here.
Some interesting takeaways re: Anthropic's models as of late:
Fable is *actually* in a class of its own.
Fable 5 leads the scoreboard at a Perfect average score of 93.9% — 11.1 points clear of the next model. It is also by far the most consistent model tested: 88.2% of its repeated cases scored perfectly across every criterion on every single repetition. Given that errors and issues quickly percolate and multiply in these chained agentic systems, this is an enormously valuable characteristic relative to competitors, and likely holds similar additional value in terms of code quality and other moment-to-moment junctures not tested by this benchmark.
Opus 4.7 was genuinely worse than Opus 4.5/4.6, but Opus 4.8 was a strong return to form
Claude Opus 4.7 was widely criticized for being far too stingy in its effort, perceived as a strategy by Anthropic to manage intense compute constraints at launch time. The testing bears this out empirically: Opus 4.5 and 4.6 scored at 73.3% and 71.1%, respectively, Opus 4.7 came in at 68.4%, and Opus 4.8 returned to form at 79.6%. The 4.7 dip is even more pronounced when focusing only on critical criteria completion (“Critical-only”: scores counting just the must-pass criteria): 83.1%/83.9%/75.3%/89.1% across the four Opus releases.
Sonnet 4.6 is an enormously high performer relative to its cost
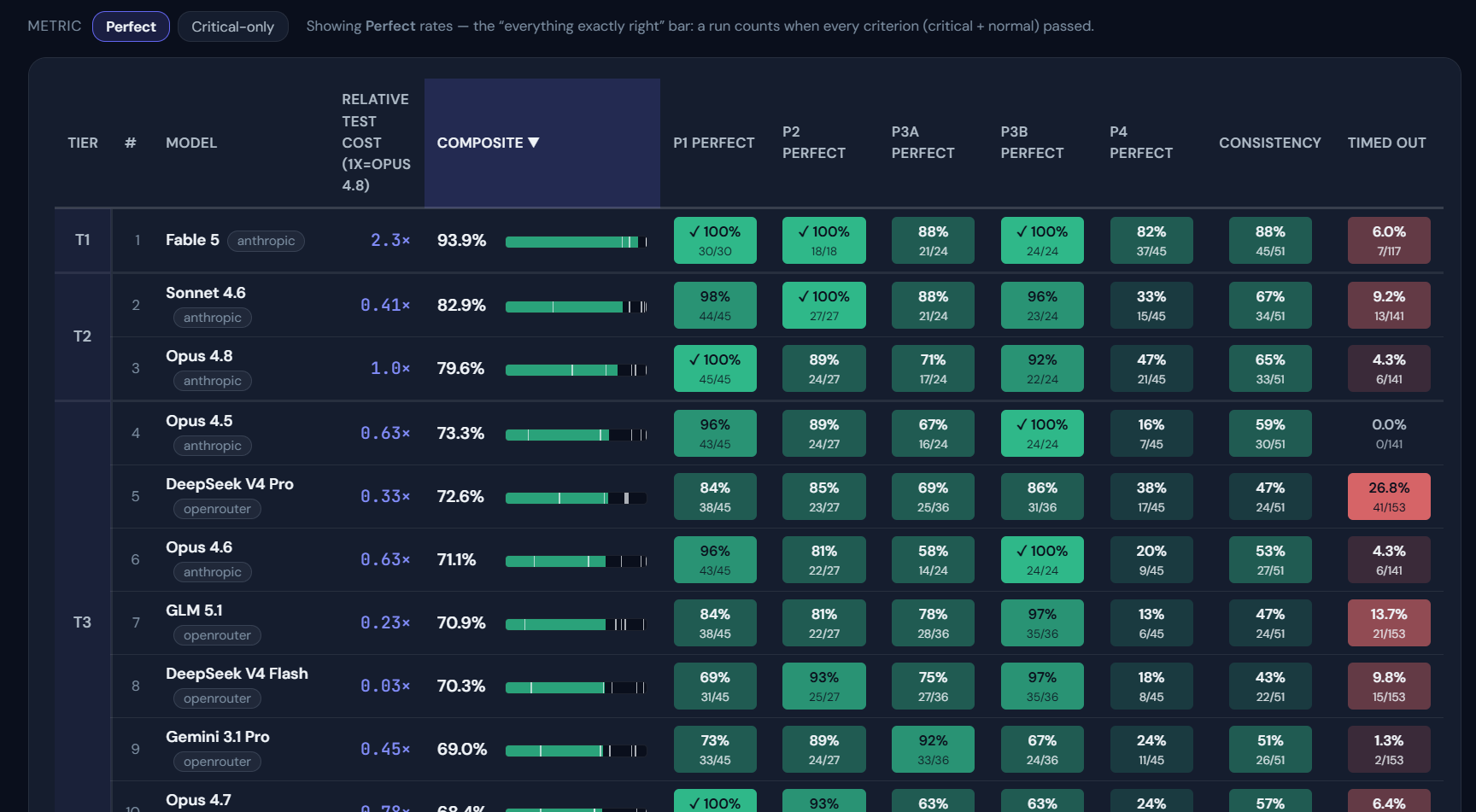
Sonnet 4.6 posts a Perfect average score of 82.9% — #2 overall, shockingly ahead of every Opus model in this corpus (best Opus: 79.6%) except in the Critical-only category. And it does so cheaply: running this benchmark’s full battery on Sonnet costs roughly 41% of what it costs on Opus 4.8. Recognizing that there is uncertainty/imprecision in these results, and many model capabilities not explicitly tested by these current tests, these numbers nonetheless suggest Sonnet 4.6 is more than capable of orchestration work on a budget with potentially minimal trade-off.
Very validating of my intuitions to date, and I cannot stress enough how wild it was using Fable last week. Definitely entering a new era, conditional on all the policy stuff getting figured out.
DAAF and Claude Code also allow out-of-the-box use with a whole host of broader models via OpenRouter, which allows us to examine frontier open-weight models as well. Some key takeaways there:
Open-weight models are highly capable by comparison -- a real win for self-hosting -- but with a crucial decline in consistency
DeepSeek V4 Pro (72.6%) and GLM 5.1 (70.9%) lead the open-weight pack, with the considerably cheaper DeepSeek V4 Flash a close follower (70.3%) — all landing in the same neighborhood as most of the Opus line. That being said, while much cheaper in terms of price-per-token, differences in token consumption patterns still place them in roughly the same cost bracket as Sonnet (with the exception of DeepSeek V4 Flash). The empirical trade-off then is less about price versus raw performance, and more about the value of control and performance consistency. Open-weight models allow for self-hosting, modification/fine-tuning, and long-term support guarantees (i.e., not worrying about Opus 4.5 getting sun-setted in a few months when multiple analyses and products rely explicitly on it). But the testing battery also reveals a marked drop in performance consistency: the Anthropic models perform predictably for the same tasks (for better and for worse), while the open-weight models perform more erratically on repeated runs. Moreover, DeepSeek Pro carries the corpus’s second-highest timeout rate (26.8% of runs) across all models tested, so its scores come with a broader reliability asterisk as well.
Local-class open-weight models just aren’t there yet, unfortunately
Qwen 3.6 27B, the best of the small open models here, manages 61.9%, and it’s at its weakest in perhaps the most important part of the overall orchestration pipeline: careful skill routing (basically: How often does it load the necessary grounding references before it responds to questions? 31.1%) and mode classification (basically: How often does it correctly assign a natural language query to the right workflow process? 46.7%). Gemma 4 31B timed out on 70 of 153 (45.8%) of its runs, often (per transcripts) not actually doing any work at all when queried: by far the worst reliability in the corpus. Some of these results may be simple harness incompatibility (Claude Code is not optimized for communicating with Gemma or Qwen, to be clear), but nonetheless point to more necessary improvements/development to be viable for rigorous research orchestration workflows. That being said, they will get there someday, and with DAAFBench, we’ll now be able to know when they do!
IMO, these are *the* frontiers to watch for a truly hopeful democratization of research capacity via AI! Self-hosting and governance, especially for sensitive data analysis work and research, are enormously valuable and unlock a ton of important use-cases. Local-hosting (i.e., being able to run this sort of work on a single consumer-grade PC) will take some more time yet, but we're getting there slowly and surely.
There’s a LOT more to explore and learn in the full interactive website explorer; I strongly recommend bookmarking a deep dive at some point if you do any quantitative data analysis with AI assistance! Would love to hear what people see and think, especially if you have any ideas for improving the value and relevance of this specific benchmark going forward. Many more models are coming out, and I intend to keep this page updated as more become available (e.g., GLM5.2, Kimi 2.7, etc.).
That’s all for now. Til next time!